轻量级虚拟化技术草稿
Support Tech
ST.1 virtiofs
ST.1.1 fuse framework
引用wiki中关于fuse的定义:
Filesystem in Userspace (FUSE) is a software interface for Unix and Unix-like computer operating systems that lets non-privileged users create their own file systems without editing kernel code. This is achieved by running file system code in user space while the FUSE module provides only a bridge to the actual kernel interfaces.
其代码框架如下:
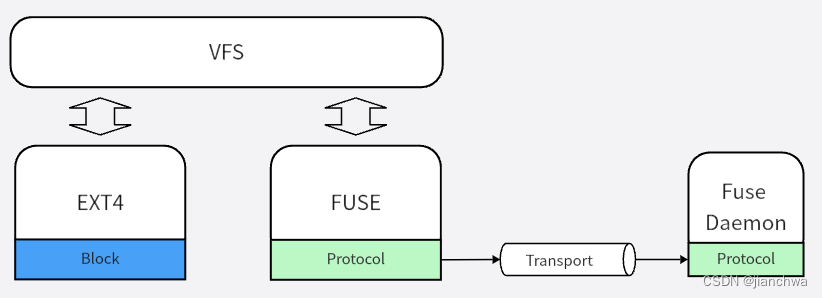
主要分为三部分:
- 内核Fuse Filsystem Client,对接Linux Kernel的VFS
- Fuse协议,其中包括了op code及其参数格式,参考GitHub - libfuse/libfuse: The reference implementation of the Linux FUSE (Filesystem in Userspace) interfaceThe reference implementation of the Linux FUSE (Filesystem in Userspace) interface - GitHub - libfuse/libfuse: The reference implementation of the Linux FUSE (Filesystem in Userspace) interface
 https://github.com/libfuse/libfuse
https://github.com/libfuse/libfuse
- Fuse传输层,目前包括两种,本地char设备和virtio
参考代码:
fuse_do_readpage()
---
...
loff_t pos = page_offset(page);
struct fuse_page_desc desc = { .length = PAGE_SIZE };
struct fuse_io_args ia = {
.ap.args.page_zeroing = true,
.ap.args.out_pages = true,
.ap.num_pages = 1,
.ap.pages = &page,
.ap.descs = &desc,
};
...
fuse_wait_on_page_writeback(inode, page->index);
...
fuse_read_args_fill(&ia, file, pos, desc.length, FUSE_READ);
res = fuse_simple_request(fm, &ia.ap.args);
...
SetPageUptodate(page);
---
fuse_lookup_name()
---
fuse_lookup_init(fm->fc, &args, nodeid, name, outarg);
---
args->opcode = FUSE_LOOKUP;
args->nodeid = nodeid;
args->in_numargs = 1;
args->in_args[0].size = name->len + 1;
args->in_args[0].value = name->name;
args->out_numargs = 1;
args->out_args[0].size = sizeof(struct fuse_entry_out);
args->out_args[0].value = outarg;
// fuse_entry_out.attr includes all of inode attributes, such as ino/size/blocks/atime/mtime/ctime/nlink/mode/uid/gid ...
---
err = fuse_simple_request(fm, &args);
...
*inode = fuse_iget(sb, outarg->nodeid, outarg->generation,
&outarg->attr, entry_attr_timeout(outarg),
attr_version);
---
fuse_simple_request()
---
if (args->force) {
atomic_inc(&fc->num_waiting);
req = fuse_request_alloc(fm, GFP_KERNEL | __GFP_NOFAIL);
...
__set_bit(FR_WAITING, &req->flags);
__set_bit(FR_FORCE, &req->flags);
} else {
req = fuse_get_req(fm, false);
...
}
...
__fuse_request_send(req);
...
fuse_put_request(req);
---
__fuse_request_send()
-> spin_lock(&fiq->lock);
-> queue_request_and_unlock()
---
list_add_tail(&req->list, &fiq->pending);
fiq->ops->wake_pending_and_unlock(fiq);
---
-> request_wait_answer()
---
if (!fc->no_interrupt) {
/* Any signal may interrupt this */
err = wait_event_interruptible(req->waitq,
test_bit(FR_FINISHED, &req->flags));
...
}
if (!test_bit(FR_FORCE, &req->flags)) {
/* Only fatal signals may interrupt this */
err = wait_event_killable(req->waitq,
test_bit(FR_FINISHED, &req->flags));
...
}
/*
* Either request is already in userspace, or it was forced.
* Wait it out.
*/
wait_event(req->waitq, test_bit(FR_FINISHED, &req->flags));
---以上代码中列举了两个常见的文件系统操作,readpage和lookup,它们都是同步的,所以,需要request_wait_answer()。
write page的处理代码如下:
fuse_writepage_locked()
---
tmp_page = alloc_page(GFP_NOFS | __GFP_HIGHMEM);
...
fuse_write_args_fill(&wpa->ia, wpa->ia.ff, page_offset(page), 0);
copy_highpage(tmp_page, page);
wpa->ia.write.in.write_flags |= FUSE_WRITE_CACHE;
wpa->next = NULL;
ap->args.in_pages = true;
ap->num_pages = 1;
ap->pages[0] = tmp_page;
ap->descs[0].offset = 0;
ap->descs[0].length = PAGE_SIZE;
ap->args.end = fuse_writepage_end;
wpa->inode = inode;
inc_wb_stat(&inode_to_bdi(inode)->wb, WB_WRITEBACK);
inc_node_page_state(tmp_page, NR_WRITEBACK_TEMP);
spin_lock(&fi->lock);
tree_insert(&fi->writepages, wpa);
list_add_tail(&wpa->queue_entry, &fi->queued_writes);
fuse_flush_writepages(inode);
spin_unlock(&fi->lock);
end_page_writeback(page);
---
fuse_writepages()
---
err = write_cache_pages(mapping, wbc, fuse_writepages_fill, &data);
if (data.wpa) {
WARN_ON(!data.wpa->ia.ap.num_pages);
fuse_writepages_send(&data);
}
---
fuse_writepages_send()
---
spin_lock(&fi->lock);
list_add_tail(&wpa->queue_entry, &fi->queued_writes);
fuse_flush_writepages(inode);
spin_unlock(&fi->lock);
for (i = 0; i < num_pages; i++)
end_page_writeback(data->orig_pages[i]);
---
fuse_flush_writepages()
-> fuse_send_writepage()
-> fuse_simple_background()
-> fuse_request_queue_background()
---
if (likely(fc->connected)) {
fc->num_background++;
if (fc->num_background == fc->max_background)
fc->blocked = 1;
if (fc->num_background == fc->congestion_threshold && fm->sb) {
set_bdi_congested(fm->sb->s_bdi, BLK_RW_SYNC);
set_bdi_congested(fm->sb->s_bdi, BLK_RW_ASYNC);
}
list_add_tail(&req->list, &fc->bg_queue);
flush_bg_queue(fc);
queued = true;
}
---
fuse_send_writepage()
---
fi->writectr++;
---
fuse_writepage_end()
---
fi->writectr--;
fuse_writepage_finish(fm, wpa);
---
for (i = 0; i < ap->num_pages; i++) {
dec_wb_stat(&bdi->wb, WB_WRITEBACK);
dec_node_page_state(ap->pages[i], NR_WRITEBACK_TEMP);
wb_writeout_inc(&bdi->wb);
}
wake_up(&fi->page_waitq);
---
---
fuse_fsync()
-> file_write_and_wait_range()
-> fuse_sync_writes(inode)
-> fuse_set_nowrite()
---
spin_lock(&fi->lock);
BUG_ON(fi->writectr < 0);
fi->writectr += FUSE_NOWRITE;
spin_unlock(&fi->lock);
wait_event(fi->page_waitq, fi->writectr == FUSE_NOWRITE);
---
---
write page中最大的不同在于:fuse申请了一个tmp_page,然后使用这个tmp_page去承载数据,并发给对端;发出去之后,立刻就调用了end_page_writeback(),此时page cache中的数据还没有真正落盘;数据落盘的语义最终是通过fsync保证的。这样就避免了用户态fuse daemon故障导致系统dirty pages无人处理。
对与这个设计,fuse的commit的comment中做了解释:
Fuse page writeback design
--------------------------
fuse_writepage() allocates a new temporary page with GFP_NOFS|__GFP_HIGHMEM.
It copies the contents of the original page, and queues a WRITE request to the
userspace filesystem using this temp page.
The writeback is finished instantly from the MM's point of view: the page is
removed from the radix trees, and the PageDirty and PageWriteback flags are
cleared.
For the duration of the actual write, the NR_WRITEBACK_TEMP counter is
incremented. The per-bdi writeback count is not decremented until the actual
write completes.
On dirtying the page, fuse waits for a previous write to finish before
proceeding. This makes sure, there can only be one temporary page used at a
time for one cached page.
This approach is wasteful in both memory and CPU bandwidth, so why is this
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
complication needed?
The basic problem is that there can be no guarantee about the time in which
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
the userspace filesystem will complete a write. It may be buggy or even
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
malicious, and fail to complete WRITE requests. We don't want unrelated parts
of the system to grind to a halt in such cases.
Also a filesystem may need additional resources (particularly memory) to
complete a WRITE request. There's a great danger of a deadlock if that
allocation may wait for the writepage to finish.