Linux系统下C语言的编程技巧
Linux系统能够为人们提供更加安全实用的效果,保证计算机系统能够稳定的运行。利用Linux系统下首先要进行C语言的编程,掌握编程的技巧能够更好的发挥计算机的作用。如何掌握Linux系统下计算机C语言的编程技巧是计算机发展的关键要素。本文对Linux系统下计算机C语言的编程技巧进行相应的分析。
以下是一些Linux系统下C语言编程的技巧:
1、使用头文件
在C语言中,头文件是一种包含函数原型、宏定义和结构体声明等信息的文件。在Linux系统下,常用的头文件包括stdio.h、stdlib.h、string.h、unistd.h等。使用头文件可以方便地引入所需的函数和数据类型,提高代码的可读性和可维护性。
2、使用Makefile
Makefile是一种用于自动化编译程序的工具。在Linux系统下,使用Makefile可以方便地管理程序的编译和链接过程,避免手动输入编译命令的繁琐和容易出错。
3、使用调试工具
在Linux系统下,常用的调试工具包括gdb和valgrind。gdb可以帮助开发者定位程序中的bug,而valgrind可以检测程序中的内存泄漏和其他常见的错误。
4、使用动态库
在Linux系统下,动态库是一种可以在程序运行时动态加载的库文件。使用动态库可以减小程序的体积,提高程序的运行效率和可维护性。
5、使用多线程
在Linux系统下,多线程是一种常用的并发编程技术。使用多线程可以提高程序的并发性和响应性,但也需要注意线程安全和死锁等问题。
6、使用系统调用
在Linux系统下,系统调用是一种可以访问操作系统内核功能的接口。使用系统调用可以实现文件操作、进程管理、网络通信等功能,但也需要注意系统调用的参数和返回值等细节。
7、使用日志系统
在Linux系统下,日志系统是一种可以记录程序运行状态和错误信息的工具。使用日志系统可以方便地追踪程序的运行过程和排查错误,提高程序的可靠性和可维护性。
使用C语言在Linux系统下爬虫代码示例:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netdb.h>
#define MAXLINE 4096
int main(int argc, char **argv)
{
int sockfd, n;
char recvline[MAXLINE + 1];
struct sockaddr_in servaddr;
if (argc != 2) {
printf("usage: %s <website>n", argv[0]);
exit(0);
}
if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
perror("socket error");
exit(1);
}
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(80);
if (inet_pton(AF_INET, argv[1], &servaddr.sin_addr) <= 0) {
struct hostent *hptr;
if ((hptr = gethostbyname(argv[1])) == NULL) {
perror("gethostbyname error");
exit(1);
}
memcpy(&servaddr.sin_addr, hptr->h_addr, hptr->h_length);
}
if (connect(sockfd, (struct sockaddr *)&servaddr, sizeof(servaddr)) < 0) {
perror("connect error");
exit(1);
}
char request[MAXLINE + 1];
sprintf(request, "GET / HTTP/1.1rnHost: %srnConnection: Closernrn", argv[1]);
write(sockfd, request, strlen(request));
while ((n = read(sockfd, recvline, MAXLINE)) > 0) {
recvline[n] = '';
printf("%s", recvline);
}
close(sockfd);
return 0;
}
该代码基于Socket编写,使用HTTP协议向指定URL发起GET请求,并读取服务器响应的全部数据。调用方式如下:
$ gcc crawler.c -o crawler
$ ./crawler www.example.com
其中www.example.com可以替换为目标网站的域名或IP地址。请注意,此代码仅用于演示,实际爬取网页时需要遵守网站的规定和法律法规。
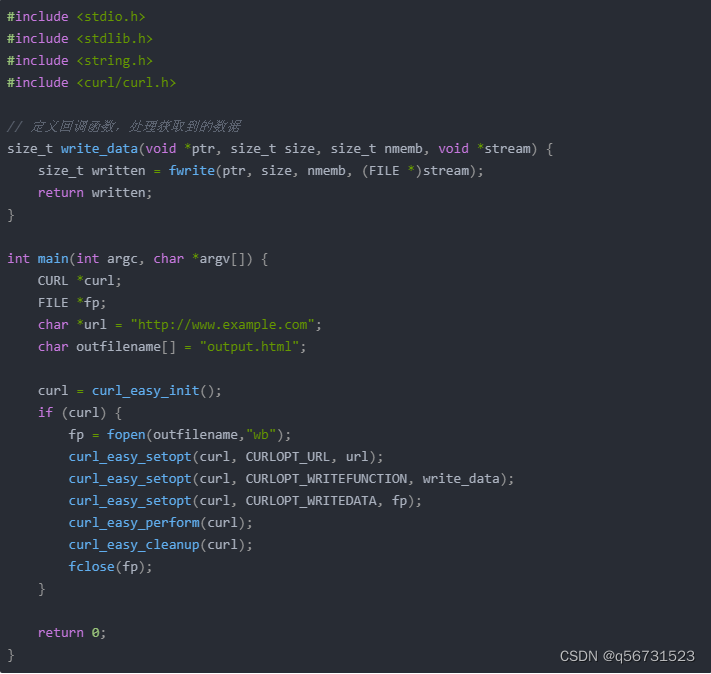
C语言爬虫代码在Linux系统下运行:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <curl/curl.h>
// 定义回调函数,处理获取到的数据
size_t write_data(void *ptr, size_t size, size_t nmemb, void *stream) {
size_t written = fwrite(ptr, size, nmemb, (FILE *)stream);
return written;
}
int main(int argc, char *argv[]) {
CURL *curl;
FILE *fp;
char *url = "http://www.example.com";
char outfilename[] = "output.html";
curl = curl_easy_init();
if (curl) {
fp = fopen(outfilename,"wb");
curl_easy_setopt(curl, CURLOPT_URL, url);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, write_data);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, fp);
curl_easy_perform(curl);
curl_easy_cleanup(curl);
fclose(fp);
}
return 0;
}
这个代码使用了libcurl库,可以通过以下命令安装:
sudo apt-get install libcurl4-openssl-dev
在代码中,我们定义了一个回调函数write_data,用于处理获取到的数据。然后,我们初始化了一个CURL对象,设置了URL和回调函数,并执行了请求。最后,我们清理CURL对象并关闭文件。
你可以将url和outfilename替换为你想要爬取的网址和输出文件名。