MYSQL中的COLLATE
概念:COLLATE 含义 核对、校对
CREATE TABLE `table1` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`field1` text COLLATE utf8_unicode_ci NOT NULL COMMENT '字段1',
`field2` varchar(128) COLLATE utf8_unicode_ci NOT NULL DEFAULT '' COMMENT '字段2',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8_unicode_ci COMMENT '测试表';mysql中字符型的列/字段 需要一个COLLATE类型来告知mysql如何对该列进行排序和比较
简而言之,COLLATE会影响到ORDER BY语句的顺序,会影响到WHERE条件中大于小于号筛选出来的结果,会影响**DISTINCT**、**GROUP BY**、**HAVING**语句的查询结果。
mysql建索引的时候,如果索引列是字符类型,也会影响索引创建
凡是涉及到字符类型比较或排序的地方,都会和COLLATE有关系
COLLATE通常是和数据编码(CHARSET)相关的,一般来说每种CHARSET都有多种它所支持的COLLATE,并且每种CHARSET都指定一种COLLATE为默认值。例如Latin1编码的默认COLLATE为latin1_swedish_ci,GBK编码的默认COLLATE为gbk_chinese_ci,utf8mb4编码的默认值为utf8mb4_general_ci
注意:建表时 DEFAULT CHARSET=utf8mb3 之前,现在多写为 DEFAULT CHARSET=utf8mb4 (表情符号如:微信☺—占据4bytes)
区分charset 与collate不同
charset设置字符串编码集,常用的utf8,mysql遗留问题utf8最存储3字节的大小,4字节的文字无法存储,需要utf8mb4
collate和charset关联,定义了字符串的排序规则,如utf8mb4_general_ci是和utf8mb4对应的排序规则,ci为Case Insensitive,即大小写不敏感
对应cs为Case Sensitive,即大小写敏感 【where name='A'与name='a'效果一致!ci不敏感时】
查看数据库的所有charset和collate
SHOW CHARACTER SET;
SHOW COLLATION;
- 设置collate的级别【库、表和字段】
- 库 CREATE DATABASE <db_name> DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
- 表 CREATE TABLE tablename (
`name` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
...
...
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;- SQL级别查询 显示声明覆盖表中的COLLATE设置
SELECT DISTINCT field1 COLLATE utf8mb4_general_ci FROM table1;
SELECT field1, field2 FROM table1 ORDER BY field1 COLLATE utf8mb4_general_ci;- 优先级顺序是 SQL语句 > 列级别设置 > 表级别设置 > 库级别设置 > 实例级别设置
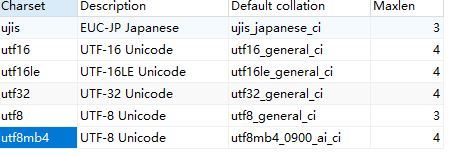
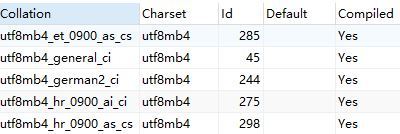
额外对比-常用utf8mb4_general_ci
utf8mb4_general_ci : 不区分大小写, utf8mb4_general_cs 区分大小写
utf8mb4_bin : 将字符串每个字符串用二进制数据编译存储,区分大小写,而且可以存二进制的内容。
utf8mb4_unicode_ci : 校对规则仅部分支持Unicode校对规则算法,一些字符还是不能支持;utf8mb4_unicode_ci不能完全支持组合的记号。
项目遇到的问题
不同表同一字段,创建的数据库表指定字符串排序规则为
utf8mb4_general_ci和utf8mb4_unicode_ci两种,导致关联无法比较
【charset不同实际问题:慢SQL,查询速度巨慢!!】
【collate不同实际问题:无法关联,报错!!】
-- 错误 SELECT a.mobile from play a INNER JOIN user_t b ON a.mobile = b.mobile
--正确 SELECT a.mobile from play a INNER JOIN user_t b ON a.mobile = b.mobile COLLATE utf8mb4_general_ci [显示转为与a的collate规则一致!]
注意:一般情况下同数据库中表的字段排序类型都是相同的!,除非开发者不小心导致
修改charset或collate
实际开发中,我建错表的charset[uat与生成环境不同!按理需要一致的]
处理:将表中数据转换;修改表的默认字符集
修改库的默认字符集
alter database XXX default character set utf8mb4 COLLATE utf8mb4_unicode_ci;
修改表的默认字符集
ALTER TABLE XXX DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
将表中原来的数据转换为utf8mb4
ALTER TABLE XXX CONVERT TO CHARACTER SET utf8mb4;
修改列字符集
ALTER TABLE XXX CHANGE column_name VARCHAR(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;