一文拿捏分布式、分布式缓存及其问题解决
1.分布式
1.集中式
传统的计算模型通常是集中式的,所有的计算任务和数据处理都由单一的计算机或服务器完成。然而,随着数据量和计算需求的增加,集中式系统可能会面临性能瓶颈和可靠性问题。
故而引出了分布式↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
2.分布式
分布式是一种利用多台计算机协同工作来完成任务的计算模型。
分布式系统的目标是通过将任务和数据分割成小块,将计算任务分发到不同的计算节点上,充分利用多台计算机的处理能力,以应对大规模的计算需求,以提高性能、可扩展性和容错性。
分布式系统的一些问题:数据一致性、通信延迟、故障处理等。为了解决这些问题,需要使用各种技术和算法,如分布式数据库、消息队列、负载均衡、分布式存储等。
2.分布式缓存
例如:redis缓存
分布式缓存是用于存储和管理数据以提高性能和响应速度的一种技术。
通常用于加速应用程序的数据访问,减轻后端数据库或其他数据存储系统的负载。
在分布式缓存中,数据被存储在位于应用程序和数据存储系统之间的一个或多个缓存节点中。这些节点可以位于不同的服务器或计算机上,形成一个分布式的缓存网络。当应用程序需要访问数据时,它首先会查询缓存,如果缓存中存在数据,就可以快速获取而不必访问原始数据存储系统。
需要注意的问题:
-
缓存穿透
-
缓存击穿
-
缓存雪崩
-
数据一致性
1.缓存穿透
指查询一个数据库中一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录
解决方案:
1.缓存null
当数据库中查不到数据的时候,缓存一个空对象,然后给这个空对象的缓存设置一个过期时间,这样下次再查询该数据的时候,就可以直接从缓存中拿到,从而达到了减小数据库压力的目的
存在缺点:
-
需要缓存层提供更多的内存空间来缓存这些空对象,当这种空对象很多的时候,就会浪费更多的内存;
-
会导致缓存层和存储层的数据不一致,即使在缓存空对象时给它设置了一个很短的过期时间,那也会导致这一段时间内的数据不一致问题。
2.使用布隆过滤器
布隆过滤器:
布隆过滤器,就是一种数据结构,它是由一个长度为m bit的位数组与n个hash函数组成的数据结构,位数组中每个元素的初始值都是0。在初始化布隆过滤器时,会先将所有key进行n次hash运算,这样就可以得到n个位置,然后将这n个位置上的元素改为1。这样,就相当于把所有的key保存到了布隆过滤器中了。
布隆过滤器就相当于一个位于客户端与缓存层中间的拦截器一样,负责判断key是否在集合中存在
存在缺点:
有误判的可能(位数组长度越大,误判率越低): 例如:
有三个key,经hash运算后
key1: 1 、2 、4
key2: 2 、5 、6
key3: 4、 5 、6 由于4、5、6都以存在已置为1,布隆过滤器就认为key3在库中存在
2.缓存击穿
对于设置了过期时间的key(一个key),缓存在某个时间点过期了,在该热点数据重新载入缓存之前,恰好这时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把 DB 压垮。
解决方案:
1.永远不过期
-
不对这个key设置过期时间
-
正常给key设置过期时间,同时在后台同时启一个定时任务去定时地更新这个缓存
2.使用分布式锁
同一时刻只能有一个查询请求重新加载热点数据到缓存中。
这样,其他的线程只需等待该线程运行完毕,即可重新从Redis中获取数据
整体的思想:获取锁的时候向Redis中插入数据,释放锁的时候从Redis中删除数据。
使用的命令: setnx
详细往下看↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
3.缓存雪崩
当缓存中有大量的key在同一时刻过期,或者Redis直接宕机了,导致大量的查询请求全部到达数据库,造成数据库查询压力骤增,甚至直接挂掉
解决方案:
1.添加过期随机数,使key均匀失效
将key的过期时间后面加上一个随机数,这个随机数值的范围可以根据自己的业务情况自行设定,这样可以让key均匀的失效,避免大批量的同时失效。
4.数据一致性问题
因为数据库与缓存是不同的组件,操作必须有先后顺序,无法像数据库的事务一样满足ACID的特性,所以就会出现数据在缓存中与在数据
库中不一致的问题。
在更新的时候,操作缓存和数据库无疑就是以下四种可能之一:
1.双写模式:
-
先更新缓存,再更新数据库
-
先更新数据库,再更新缓存
2.失效模式:
-
先删除缓存,再更新数据库
-
先更新数据库,再删除缓存
1.先更新缓存,在更新数据库
如果我成功更新了缓存,但是在执行更新数据库的那一步,服务器突然宕机了,那么此时,我的缓存中是最新的数据,而数据库中是旧的数据。
2.先更新数据库,在更新缓存
如果我成功更新了数据库,但是在执行更新缓存的那一步,服务器突然宕机了,那么此时,我的缓存中就是老数据,而数据库中是新的数据。
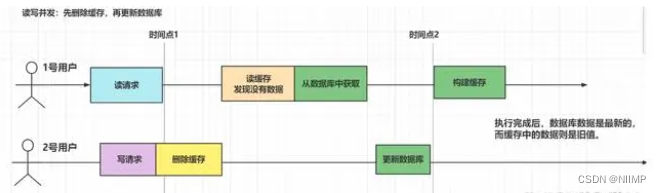
3.先删除缓存,在更新数据库
非高并发情况下可保证数据一致性:
若删除缓存成功,更新数据库失败,下次操作会去数据库中获取该数据,并将最新数据写入缓存
读写发情况下会出现数据不一致问题:
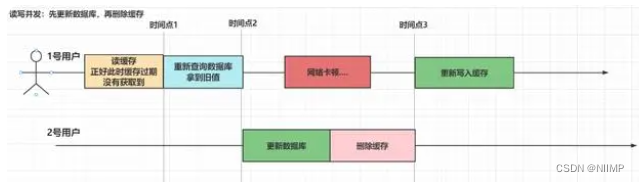
4.先更新数据库,在删除缓存
1.更新数据库成功了,而删除缓存失败
数据库中就会是新数据,而缓存中是旧数据,数据就出现了不一致情况:

2.更新数据库成功了,删除缓存也执行成功
还是会造成数据的不一致性
但是此处达成这个数据不一致性的条件明显会比起其他的方式更为困难 :
-
时刻1:读请求的时候,缓存正好过期
-
时刻2:读请求在写请求更新数据库之前查询数据库,
-
时刻3:写请求,在更新数据库之后,要在读请求成功写入缓存前,先执行删除缓存操作。
这通常是很难做到的,因为在真正的并发开发中,更新数据库是需要加锁的,不然没一点安全性
5.延迟双删
先进行缓存清除,在更新数据库,最后(延迟N秒确保数据库已更新)再执行缓存清除。进行两次删除,且中间需要延迟一段时间
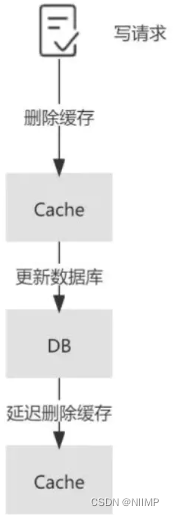
上述方案在极端情况下,如果第三步删除失败仍然可能导致数据一致性问题,解决方案有: