torch.nn.MSELoss扒开看看它
官网介绍

Toy
设 X , Y ∈ R n × d mathbf{X} , mathbf{Y} in mathbf{R}^{ntimes d} X,Y∈Rn×d,假设其中 X mathbf{X} X是模型的输入, Y mathbf{Y} Y是真实标签
默认参数
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
如果在模型训练中直接使用MSELoss,即
loss = torch.nn.MSELoss()
loss = loss(X, Y)
print(loss)
loss.backward()
print(X.grad)
则
l
o
s
s
=
1
n
×
d
∣
∣
X
−
Y
∣
∣
2
loss = frac{1} {ntimes d}||X-Y||^2
loss=n×d1∣∣X−Y∣∣2
X
.
g
r
a
d
=
∂
l
o
s
s
∂
X
=
∂
1
n
×
d
∣
∣
X
−
Y
∣
∣
2
∂
X
=
2
n
×
d
(
X
−
Y
)
X.grad = frac{partial loss}{partial X} = frac{partial frac{1} {ntimes d}||X-Y||^2}{partial X}=frac{2}{ntimes d}(mathbf{X}-mathbf{Y})
X.grad=∂X∂loss=∂X∂n×d1∣∣X−Y∣∣2=n×d2(X−Y) ,范数求导参考1
例如
X
=
[
3
1
4
2
5
3
]
,
Y
=
[
2
2
1
4
6
2
]
⇒
l
o
s
s
=
1
3
×
2
∥
3
−
2
1
−
2
4
−
1
2
−
4
5
−
6
3
−
2
∥
2
=
17
/
6
=
2.8333
mathbf{X}=begin{bmatrix} 3 & 1\ 4 & 2\ 5 & 3 end{bmatrix}, mathbf{Y}=begin{bmatrix} 2 & 2 \ 1 & 4 \ 6 & 2 end{bmatrix} Rightarrow loss = frac{1}{3times2}begin{Vmatrix} 3-2 & 1-2\ 4-1 & 2-4\ 5-6 & 3-2 end{Vmatrix}^2=17/6=2.8333
X=
345123
,Y=
216242
⇒loss=3×21
3−24−15−61−22−43−2
2=17/6=2.8333
X
.
g
r
a
d
=
2
3
×
2
[
3
−
2
1
−
2
4
−
1
2
−
4
5
−
6
3
−
2
]
=
1
3
[
1
−
1
3
−
2
−
1
−
1
]
X.grad = frac{2}{3times2}begin{bmatrix} 3-2 & 1-2\ 4-1 & 2-4\ 5-6 & 3-2 end{bmatrix}= frac{1}{3}begin{bmatrix} 1 & -1\ 3 & -2\ -1 & -1 end{bmatrix}
X.grad=3×22
3−24−15−61−22−43−2
=31
13−1−1−2−1
代码实现
import torch
X = torch.tensor([[3, 1], [4, 2], [5, 3]], dtype=torch.float, requires_grad=True)
Y = torch.tensor([[2, 2], [1, 4], [6, 2]], dtype=torch.float)
loss = torch.nn.MSELoss()
loss = loss(X, Y)
loss.backward()
print(loss)
# tensor(2.8333, grad_fn=<MseLossBackward0>)
print(X.grad)
#tensor([[ 0.3333, -0.3333],
# [ 1.0000, -0.6667],
# [-0.3333, 0.3333]])
定制参数
torch.nn.MSELoss(reduction='sum')
如果在模型训练中使用MSELoss(reduction='sum'),即
loss = torch.nn.MSELoss(reduction='sum')
loss = loss(X, Y)
print(loss)
loss.backward()
print(X.grad)
则
l
o
s
s
=
∣
∣
X
−
Y
∣
∣
2
loss =||X-Y||^2
loss=∣∣X−Y∣∣2
X
.
g
r
a
d
=
∂
l
o
s
s
∂
X
=
∂
∣
∣
X
−
Y
∣
∣
2
∂
X
=
2
(
X
−
Y
)
X.grad = frac{partial loss}{partial X} = frac{partial ||X-Y||^2}{partial X}=2(mathbf{X}-mathbf{Y})
X.grad=∂X∂loss=∂X∂∣∣X−Y∣∣2=2(X−Y)
例如
X
=
[
3
1
4
2
5
3
]
,
Y
=
[
2
2
1
4
6
2
]
⇒
l
o
s
s
=
∥
3
−
2
1
−
2
4
−
1
2
−
4
5
−
6
3
−
2
∥
2
=
17
mathbf{X}=begin{bmatrix} 3 & 1\ 4 & 2\ 5 & 3 end{bmatrix}, mathbf{Y}=begin{bmatrix} 2 & 2 \ 1 & 4 \ 6 & 2 end{bmatrix} Rightarrow loss = begin{Vmatrix} 3-2 & 1-2\ 4-1 & 2-4\ 5-6 & 3-2 end{Vmatrix}^2=17
X=
345123
,Y=
216242
⇒loss=
3−24−15−61−22−43−2
2=17
X
.
g
r
a
d
=
2
[
3
−
2
1
−
2
4
−
1
2
−
4
5
−
6
3
−
2
]
=
[
2
−
2
6
−
4
−
2
−
2
]
X.grad = 2begin{bmatrix} 3-2 & 1-2\ 4-1 & 2-4\ 5-6 & 3-2 end{bmatrix}= begin{bmatrix} 2 & -2\ 6 & -4\ -2 & -2 end{bmatrix}
X.grad=2
3−24−15−61−22−43−2
=
26−2−2−4−2
代码实现
import torch
X = torch.tensor([[3, 1], [4, 2], [5, 3]], dtype=torch.float, requires_grad=True)
Y = torch.tensor([[2, 2], [1, 4], [6, 2]], dtype=torch.float)
loss = torch.nn.MSELoss(reduction='sum')
loss = loss(X, Y)
loss.backward()
print(loss)
# tensor(17., grad_fn=<MseLossBackward0>)
print(X.grad)
#tensor([[ 2., -2.],
# [ 6., -4.],
# [-2., 2.]])
预测问题-线性回归
为了解释线性回归,我们举一个实际的例子2: 我们希望根据房屋的面积(平方英尺)和房龄(年)来估算房屋价格(美元)。
使用
n
n
n来表示数据集中的样本数。对索引为
i
i
i的样本,其输入表示为
x
(
i
)
=
[
x
1
(
i
)
,
x
2
(
i
)
]
⊤
mathbf{x}^{(i)} = [x_1^{(i)}, x_2^{(i)}]^top
x(i)=[x1(i),x2(i)]⊤,其对应的标签是
y
(
i
)
y^{(i)}
y(i)。
线性假设是指目标(房屋价格)可以表示为特征(面积和房龄)的加权和,如下面的式子:
p r i c e = w a r e a ⋅ a r e a + w a g e ⋅ a g e + b . mathrm{price} = w_{mathrm{area}} cdot mathrm{area} + w_{mathrm{age}} cdot mathrm{age} + b. price=warea⋅area+wage⋅age+b.
给定一个数据集,我们的目标是寻找模型的权重 w = [ w 1 , w 2 ] mathbf{w}=[w_1, w_2] w=[w1,w2]和偏置 b b b,使得根据模型做出的预测大体符合数据里的真实价格。
这里为了手算简单,我们使用的数据集有6个样本
X
∈
R
6
×
2
,
y
∈
R
6
mathbf{X}inmathbf{R}^{6times 2},mathbf{y}in mathbf{R}^6
X∈R6×2,y∈R6。
即
X
=
[
1
2
4
2
8
1
0
1
3
8
1
3
]
,
y
=
[
1
6
2
7
1
3
]
mathbf{X}=begin{bmatrix} 1 & 2\ 4 & 2\ 8 & 1\ 0 & 1\ 3 & 8\ 1 & 3 end{bmatrix},mathbf{y}=begin{bmatrix} 1 \ 6\ 2\ 7\ 1\ 3 end{bmatrix}
X=
148031221183
,y=
162713
。
麻雀虽小五脏俱全,我们将这6个样本分批训练,即batch_size = 3,同时为了复现上述的线性假设,我们使用nn.Linear(2, 1),即含有三个可学习的参数,分别是模型的权重
w
=
[
w
1
,
w
2
]
mathbf{w}=[w_1, w_2]
w=[w1,w2]和偏置
b
b
b,我们初始化模型参数为
w
0
=
[
1
,
2
]
mathbf{w_0}=[1, 2]
w0=[1,2]和偏置
b
0
b_0
b0=0。这里也使用常用的优化算法stochastic gradient descent,即torch.optim.SGD()。进一步方便手算,我们使用的学习率lr = 0.5。训练之前的代码如下
import numpy as np
import torch
from torch.utils import data
# 为了手算理解内部计算过程,我们手动随便输入数据组成数据集
# 这里的数据集有6个数据样本,每个样本有两个特征
features = torch.tensor([[1, 2], [4, 2], [8, 1], [0, 1], [3, 8], [1, 3]], dtype=torch.float)
labels = torch.tensor([[1], [6], [2], [7], [1], [3]], dtype=torch.float)
# print(features, 'n', labels)
def load_array(data_arrays, batch_size, is_train=True):
"""构造一个PyTorch数据迭代器"""
# 布尔值is_train表示是否希望数据迭代器对象在每个迭代周期内打乱数据。
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
# 因为数据集有6个样本,所以这里批大小可以是3,为了理解而服务
batch_size = 3
data_iter = load_array((features, labels), batch_size)
# nn是神经网络的缩写
from torch import nn
# y = x_1*w_1 + x_2*w_2 + b
net = nn.Sequential(nn.Linear(2, 1))
# 手动初始化两个权重和偏置
net[0].weight.data = torch.tensor([[1, 2]], dtype=torch.float)
net[0].bias.data.fill_(0)
# print(net[0].weight.data, 'n', net[0].bias.data)
# 这里使用均方误差,即2范数的平方和,在训练迭代过程中要除以batch_size
loss=torch.nn.MSELoss(reduction='sum')
trainer = torch.optim.SGD(net.parameters(), lr=0.5)
训练过程:
在每个迭代周期里,我们将完整遍历一次数据集(train_data),不停地从中获取一个小批量的输入和相应的标签。对于每一个小批量,我们会进行以下步骤:
- 通过调用net(X)生成预测并计算损失l(前向传播)。
- 通过进行反向传播来计算梯度。
- 通过调用优化器来更新模型参数。
为了更好的衡量训练效果,我们计算每个迭代周期后的损失,并打印它来监控训练过程。
# 训练周期为3
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
# print('X: ', X, ',y :', y)
# print(len(y))
# len(y)是批量大小,这里是为了让学习率与批量大小解耦
l = loss(net(X) ,y)/len(y)
# print('l:', l)
trainer.zero_grad()
l.backward()
# print('net[0].weight.data: ',net[0].weight.data,'nnet[0].bias.data: ', net[0].bias.data)
# print('w.grad: ', net[0].weight.grad, 'nb.grad: ', net[0].bias.grad)
trainer.step()
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')
每个训练周期中,因为
b
a
t
c
h
_
s
i
z
e
=
3
batch_size=3
batch_size=3,所以一共有
n
/
b
a
t
c
h
_
s
i
z
e
=
6
/
3
n/batch_size=6/3
n/batch_size=6/3个批次,假设
e
p
o
c
h
0
epoch mathbf{0}
epoch0的第一批抽取的3个样本组成的输入特征
X
∈
R
3
×
2
mathbf{X}inmathbf{R}^{3times 2}
X∈R3×2和标签
y
∈
R
3
mathbf{y}inmathbf{R}^3
y∈R3,分别(这里因为每批次的样本是从数据集中随机抽取的,所以具体运行因人而异)是
X
=
[
1
3
4
2
1
2
]
,
y
=
[
3
6
1
]
mathbf{X}=begin{bmatrix} 1 & 3\ 4 & 2\ 1 & 2\ end{bmatrix}, mathbf{y}=begin{bmatrix} 3\ 6\ 1\ end{bmatrix}
X=
141322
,y=
361
,则
l
o
s
s
=
1
∣
b
a
t
c
h
_
s
i
z
e
∣
∣
∣
X
w
+
b
−
y
∣
∣
2
=
1
3
∥
[
1
3
4
2
1
2
]
[
1
2
]
+
[
0
0
0
]
−
[
3
6
1
]
∥
2
=
12
loss =frac{1}{|mathbf{batch_size}|}||Xmathbf{w}+mathbf{b}-y||^2=frac{1}{3}begin{Vmatrix} begin{bmatrix} 1 & 3\ 4 & 2\ 1 & 2\ end{bmatrix} begin{bmatrix} 1\ 2 end{bmatrix}+ begin{bmatrix} 0\ 0\ 0 end{bmatrix}- begin{bmatrix} 3\ 6\ 1 end{bmatrix} end{Vmatrix}^2=12
loss=∣batch_size∣1∣∣Xw+b−y∣∣2=31
141322
[12]+
000
−
361
2=12,
w
.
g
r
a
d
=
∂
l
o
s
s
∂
w
=
∂
1
∣
b
a
t
c
h
_
s
i
z
e
∣
∣
∣
X
w
+
b
−
y
∣
∣
2
∂
w
=
2
∣
b
a
t
c
h
_
s
i
z
e
∣
X
T
(
X
w
+
b
−
y
)
=
2
3
[
1
3
4
2
1
2
]
T
(
[
1
3
4
2
1
2
]
[
1
2
]
+
[
0
0
0
]
−
[
3
6
1
]
)
=
[
32
3
16
]
mathbf{w}.grad= frac{partial loss}{partial mathbf{w}} = frac{partial frac{1}{|mathbf{batch_size}|}||Xmathbf{w}+mathbf{b}-y||^2}{partial mathbf{w}}=frac{2}{|mathbf{batch_size}|}X^{T}(Xmathbf{w}+mathbf{b}-y)=frac{2}{3}begin{bmatrix} 1 & 3\ 4 & 2\ 1 & 2\ end{bmatrix} ^{T}(begin{bmatrix} 1 & 3\ 4 & 2\ 1 & 2\ end{bmatrix} begin{bmatrix} 1\ 2 end{bmatrix}+begin{bmatrix} 0\ 0\ 0 end{bmatrix}-begin{bmatrix} 3\ 6\ 1 end{bmatrix})=begin{bmatrix} mathbf{frac{32}{3}}\ mathbf{16} end{bmatrix}
w.grad=∂w∂loss=∂w∂∣batch_size∣1∣∣Xw+b−y∣∣2=∣batch_size∣2XT(Xw+b−y)=32
141322
T(
141322
[12]+
000
−
361
)=[33216](这里偏置
b
mathbf{b}
b使用了torch.tensor的广播机制3)。
值得注意的是 l o s s = 1 ∣ b a t c h _ s i z e ∣ ∣ ∣ X w + b − y ∣ ∣ 2 loss =frac{1}{|mathbf{batch_size}|}||Xmathbf{w}+mathbf{b}-y||^2 loss=∣batch_size∣1∣∣Xw+b−y∣∣2,这种形式是为了处理像这种多个维度的向量矩阵,那么对于标量 b mathbf{b} b而言, l o s s = 1 ∣ b a t c h _ s i z e ∣ ∣ ∣ X w + b − y ∣ ∣ 2 = 1 ∣ b a t c h _ s i z e ∣ ∑ i = 1 ∣ b a t c h _ s i z e ∣ ( x 1 w 1 + x 2 w 2 + b − y ) 2 = 1 3 [ ( 1 ∗ 1 + 3 ∗ 2 + 0 − 3 ) 2 + ( 4 ∗ 1 + 2 ∗ 2 + 0 − 6 ) 2 + ( 1 ∗ 1 + 2 ∗ 2 + 0 − 1 ) 2 ] = 12 loss =frac{1}{|mathbf{batch_size}|}||Xmathbf{w}+mathbf{b}-y||^2=frac{1}{|mathbf{batch_size}|}sum_{i=1}^{|batch_size|}(x_1w_1+x_2w_2+mathbf{b}-y)^2=frac{1}{3}mathbf{[}(1*1+3*2+mathbf{0}-3)^2+(4*1+2*2+mathbf{0}-6)^2+(1*1+2*2+mathbf{0}-1)^2]=12 loss=∣batch_size∣1∣∣Xw+b−y∣∣2=∣batch_size∣1∑i=1∣batch_size∣(x1w1+x2w2+b−y)2=31[(1∗1+3∗2+0−3)2+(4∗1+2∗2+0−6)2+(1∗1+2∗2+0−1)2]=12,所以 b . g r a d = ∂ l o s s ∂ b = ∂ 1 ∣ b a t c h _ s i z e ∣ ∑ i = 1 ∣ b a t c h _ s i z e ∣ ( x 1 w 1 + x 2 w 2 + b − y ) 2 ∂ b = 2 ∣ b a t c h _ s i z e ∣ ∑ i = 1 ∣ b a t c h _ s i z e ∣ ( x 1 w 1 + x 2 w 2 + b − y ) = 2 3 [ ( 1 ∗ 1 + 3 ∗ 2 + 0 − 3 ) + ( 4 ∗ 1 + 2 ∗ 2 + 0 − 6 ) + ( 1 ∗ 1 + 2 ∗ 2 + 0 − 1 ) ] = 20 3 = 6.6667 mathbf{b}.grad= frac{partial loss}{partial mathbf{b}} = frac{partial frac{1}{|mathbf{batch_size}|}sum_{i=1}^{|batch_size|}(x_1w_1+x_2w_2+mathbf{b}-y)^2}{partial mathbf{b}}=frac{2}{|mathbf{batch_size}|}sum_{i=1}^{|batch_size|}(x_1w_1+x_2w_2+mathbf{b}-y)=frac{2}{3}mathbf{[}(1*1+3*2+mathbf{0}-3)+(4*1+2*2+mathbf{0}-6)+(1*1+2*2+mathbf{0}-1)]=frac{20}{3}=mathbf{6.6667} b.grad=∂b∂loss=∂b∂∣batch_size∣1∑i=1∣batch_size∣(x1w1+x2w2+b−y)2=∣batch_size∣2∑i=1∣batch_size∣(x1w1+x2w2+b−y)=32[(1∗1+3∗2+0−3)+(4∗1+2∗2+0−6)+(1∗1+2∗2+0−1)]=320=6.6667。
运行截图:
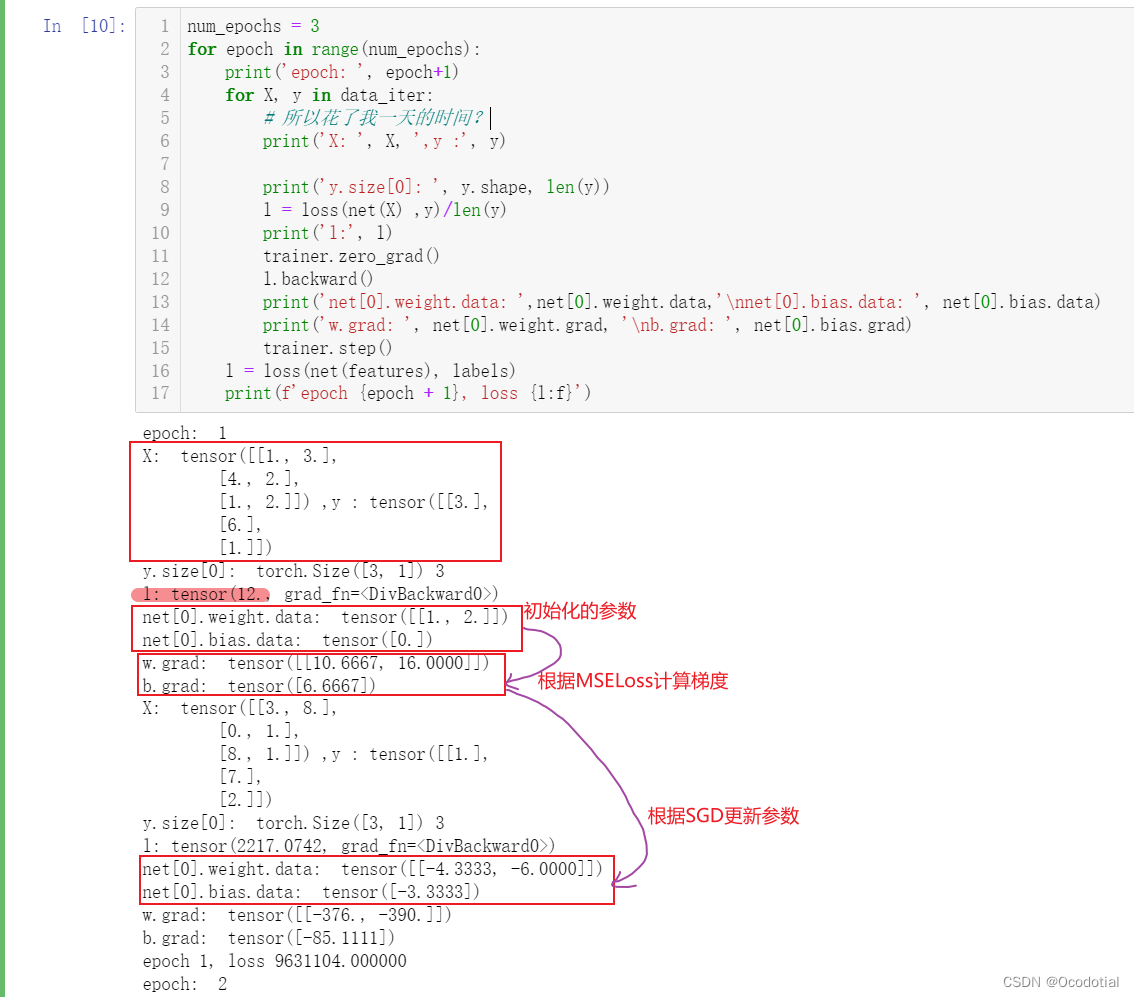
同时可学习的参数
w
mathbf{w}
w和
b
mathbf{b}
b通过SGD得到更新,即
w
1
=
w
0
−
η
∂
l
o
s
s
∂
w
=
w
0
−
η
w
.
g
r
a
d
=
[
1
2
]
−
0.5
∗
[
10.6667
16
]
=
[
−
4.3333
−
6
]
mathbf{w_1}=mathbf{w_0}-etafrac{partial loss}{partial mathbf{w}}=mathbf{w_0}-etamathbf{w}.grad=begin{bmatrix} 1\ 2 end{bmatrix}-0.5*begin{bmatrix} 10.6667\ 16 end{bmatrix}=begin{bmatrix} -4.3333\ -6 end{bmatrix}
w1=w0−η∂w∂loss=w0−ηw.grad=[12]−0.5∗[10.666716]=[−4.3333−6]和偏置
b
1
=
b
0
−
η
∂
l
o
s
s
∂
b
=
b
0
−
η
b
.
g
r
a
d
=
0
−
0.5
∗
6.6667
=
−
3.3333
mathbf{b_1}=mathbf{b_0}-etafrac{partial loss}{partial mathbf{b}}=mathbf{b_0}-etamathbf{b}.grad=0-0.5*6.6667=-3.3333
b1=b0−η∂b∂loss=b0−ηb.grad=0−0.5∗6.6667=−3.3333。后面的更新类似迭代即可。