类ChatGPT大模型LLaMA及其微调模型
1.LLaMA
LLaMA的模型架构:RMSNorm/SwiGLU/RoPE/Transfor
mer/1-1.4T tokens
1.1对transformer子层的输入归一化
对每个transformer子层的输入使用RMSNorm进行归一化,计算如下:
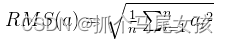
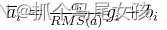
1.2使用SwiGLU替换ReLU
【Relu激活函数】Relu(x) = max(0,x) 。
【GLU激活函数】GLU(x) = x 与 sigmoid(g(x)) 对应元素相乘 。
LLaMA采用SwiGLU替换了原有的ReLU,SwiGLU的作用机制是根据输入数据的特性,通过学习到的参数自动调整信息流动的路径,具体是采用SwiGLU的Feedforward Neural Network (简称FNN,是一种使用可学习的门控机制的前馈神经网络)。xV相当于门控值,控制Swish输出的多少。
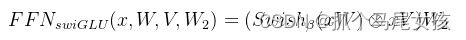
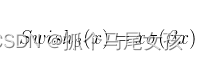
1.3位置编码
在位置编码方面,将绝对位置嵌入的方法变为相对位置嵌入。
1.4优化器的设计
使用AdamW优化器进行训练,使用余弦学习率的方式根据模型的大小动态的改变学习率和批次大小。
2.对LLaMA进行微调
2.1 Stanford Alpaca
结合英文语料通过Self Instruct的方式微调LLaMA 7B,具体通过52K的指令数据对LLaMA进行指令微调。其中52k的数据包括:指令、输入、输出。
①self-instruct方式
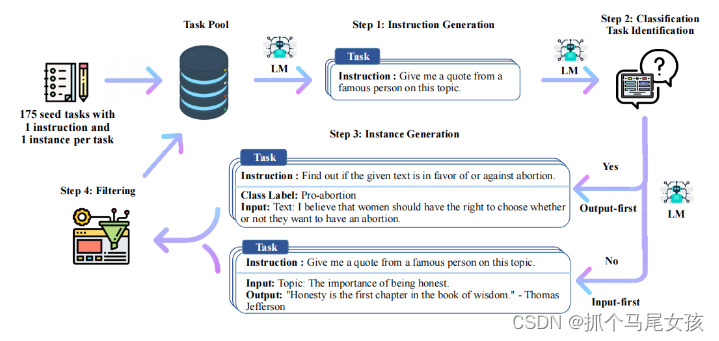
1.首选人工设计出175个种子数据集,包括指令、输入、输出。
2.使用GPT3对应的API使用种子数据集的上下文实例来生成更多新的指令。
3.使用生成的指令判断是否为分类任务。
4.使用模型生成实例。
5.生成输入和输出数据,过滤点低质量或者相似度高的数据。
6.经过过滤后的数据放入种子数据集中。
生成52K数据的完整代码:链接
②使用生成的指令数据微调LLaMA
2.2 Alpaca-LoRA
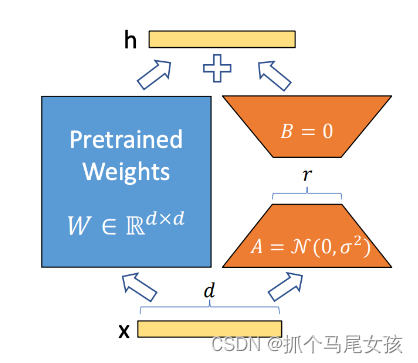
LoRA提出用两个小矩阵近似一个大矩阵,先降维(减小计算量)后升维(维持维度不变)。具体来说是固定原始模型的参数,只训练降维矩阵A与升维矩阵B。最后用原始模型参数与B矩阵相加。
LoRA层主要实现了两分支通路,一条分支为已被冻结weight参数的原始结构,另一条分支为新引入的降维再升维线性层。
2.ChatLLaMA:LLaMA的RLHF版
3.DeepSpeed Chat
具备基本生成能力的基座模型
有监督微调模型(SFT)
奖励模型(RM)
SFT、actor、RM、Critic