【Hadoop】HDFS高可用与高扩展原理分析(HA架构与Federation机制)
一、HDFS的高可用性(HA架构)
为保证HDFS的高可用性,即当NameNode节点机器出现故障而导致宕机时整个系统依旧可以维持运转,那么只需要存在多个NameNode节点即可,当前节点(Active NameNode)宕机的时候就立即切换到另外的备用节点(Standby NameNode)。这就所谓的HA(High Available)结构的基础架构和想法,那么为了保证这一点则需要Standby NameNode随时做好准备,使其与Active NameNode的节点状态保持同步(元数据保持一致)。
HA架构中存在两个NameNode,一个是Active NameNode,是当前正在使用的NameNode;另一个是Standby NameNode,是备用的NameNode。在HA架构中不存在Secondary NameNode,因为Standby NameNode会代替它的功能,将edits文件整合为fsimage文件。
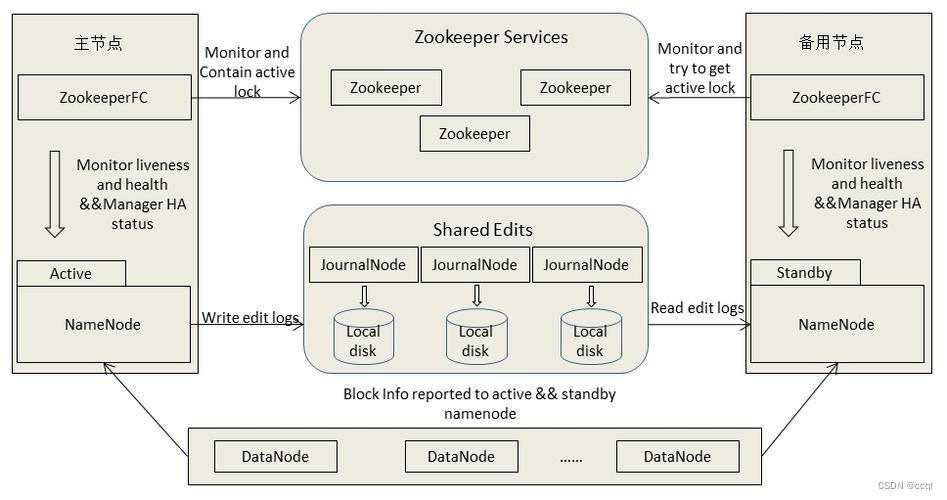
如上图所示,DataNode需要向Active NameNode和Standby NameNode分别发送block块的位置信息,且HA结构中还构建了一组Journal Nodes用以同步Active NameNode和Standby NameNode的edits文件信息,由于fsimage文件是由edits文件合并生成的,因此保证两者edits文件的同步即可。
图中的Zookeeper是为了实现自动切换NameNode功能,当多个NameNode启动的时候会分别向Zookeeper中注册一个临时节点,当它挂掉的时候,这个临时节点也就消失了,这是Zookeeper的特性。如果Zookeeper的监视器注意到当前的Active NameNode出现故障,就会立即将Standby NameNode转换为Active NameNode,将原本故障的Active NameNode转换为Standby NameNode,即使后续该节点故障被排除,也不会再切换回来,直到当前节点也出现故障才会切换回原来那个节点。
二、HDFS的高扩展性(Federation机制)
HDFS的Federation机制可以解决单一NameNode存在的问题,当集群中数据增长到一定规模后,NameNode 进程占用的内存可能会达到成百上千 GB,此时NameNode成了集群的性能瓶颈。通俗的讲,集群启动时DataNode会向NameNode上报所有的Block块信息,每个块(无论大小)对象约占150byte,而NameNode的内存是有限的,当HDFS文件愈来愈多的时候,NameNode就会成为集群的短板(这也是为什么HDFS不适合存储小文件的原因)。使用多个NameNode,每个NameNode负责一个命令空间,这种设计可提供以下特性:
- HDFS集群扩展性。多个NameNode分管一部分目录,使得一个集群可以扩展到更多节点,不再因内存的限制制约文件存储数目。
- 性能更高效。多个NameNode管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率。
- 良好的隔离性。用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
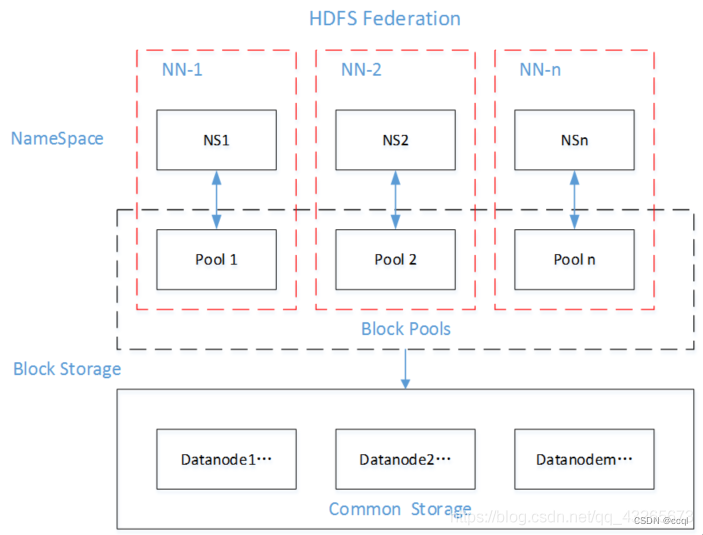
HDFS的Federation机制下存在多个NameNode,也就意味着存在多个NameSpace(命名空间),不同的NameNode分管不同的NameSpace。被同一个NameNode所管理的数据都在同一个NameSpace下,一个NameSpace对应一个Block Pool(所有数据块的集合),但每个NameNode又共用全部的DataNode资源(不同的块存储分别在不同的DataNode中)。
三、HA架构 + Federation机制
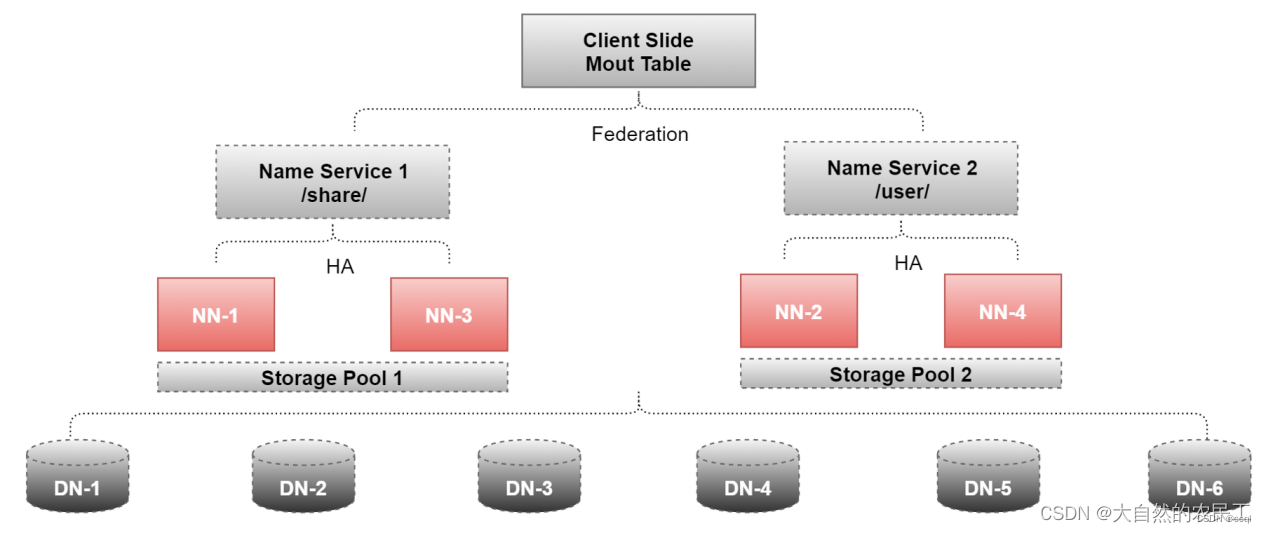
为了同时解决NameNode的单点故障问题和横向扩容问题,超大规模的集群一般都会采用HA+Federation的部署方案。从图中可以看到每个Federation机制下的NameNode都是由一个Active NameNode和一个Standby NameNode一起构成的HA架构,这样既考虑到了HDFS的高扩展性,又顾及了HDFS的高可用性。