Java-集合框架
文章目录
摘要
Java的集合框架提供了一组用于存储、管理和操作数据的类和接口。这个框架提供了各种数据结构,如列表、集合、队列和映射,以满足不同的数据处理需求。
根据实现接口可以分为:Collection、Map两大类
Collection
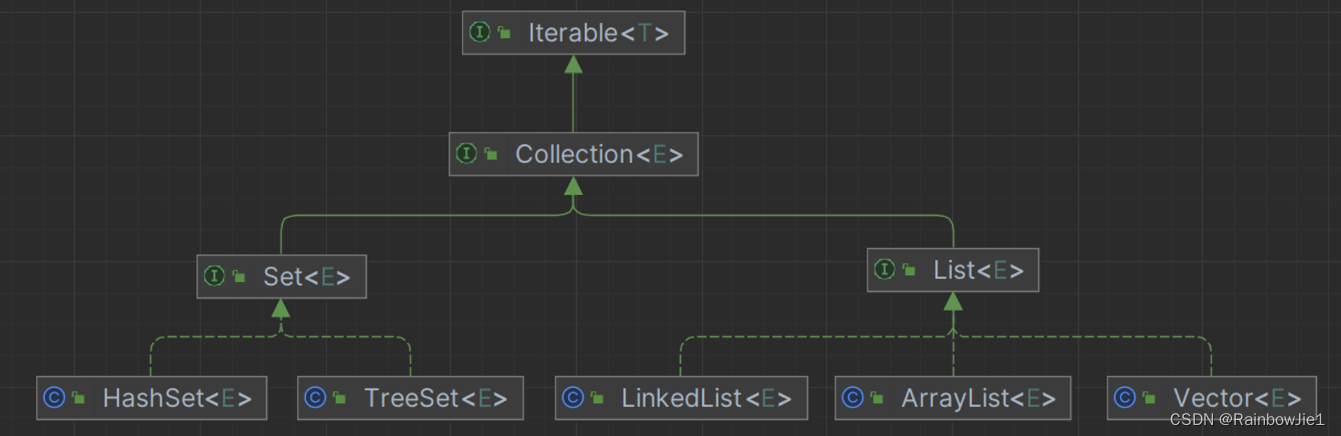
Collection集合遍历
Collection所有的实现子类集合都可以通过以下两种方式进行元素遍历:
-
Iterator迭代器 - 增强
for循环
详细的介绍如下:
Iterator迭代器
- Iterator称为迭代器,主要用于遍历Collection集合中的元素;
- 所有实现了Collection接口的集合子类都有一个Iterator()方法,返回Iterator对象,即迭代器;
执行原理:
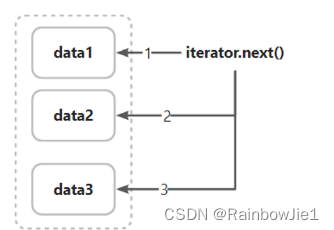
Code:
Iterator iterator=[Collection].iterator(); //创建一个迭代器
while(iterator.hasNext()){ //循环,直到集合中没有元素为止
System.out.println(iterator.next()); //获取下一个元素并打印出来
}
-
iterator():方法用于获取集合的迭代器对象,这个迭代器对象用于遍历集合中的元素。 -
iterator.hasNext():它会不断检查迭代器是否有下一个元素。如果有下一个元素,则循环会继续执行。 -
iterator.next():返回下一个元素,并将迭代器的位置移动到下一个元素。 - 遍历完成后,next指针指向最后一个位置。
如果想要充值next指针,可以执行一下代码:
iterator=[Collection].iterator();
此时next指针就会指向第一位。
增强for循环
- 增强for循环底层任然是Iterator迭代器;
- 可以理解为简化版的Iterator。
Code:
List list=new ArrayList();
。。。
//增强for循环
for(Object str:list){
System.out.println(str);
}
排序
Comparable 接口和 Comparator 接口都是 Java 中用于排序的接口,它们在实现类对象之间比较大小、排序等方面发挥了重要作用:
- Comparable接口有一个
CompareTo(Object obj)方法用来排序;- 用于比较当前对象和传入对象的顺序
- -1表示当前对象小于,0表示等于,1表示大于。
public class Person implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
/**
* T重写compareTo方法实现按年龄来排序
*/
@Override
public int compareTo(Person o) {
if (this.age > o.getAge()) {
return 1;
}
if (this.age < o.getAge()) {
return -1;
}
return 0;
}
}
public static void main(String[] args) {
TreeMap<Person, String> pdata = new TreeMap<Person, String>();
pdata.put(new Person("张三", 30), "zhangsan");
pdata.put(new Person("李四", 20), "lisi");
pdata.put(new Person("王五", 10), "wangwu");
pdata.put(new Person("小红", 5), "xiaohong");
// 得到key的值的同时得到key所对应的值
Set<Person> keys = pdata.keySet();
for (Person key : keys) {
System.out.println(key.getAge() + "-" + key.getName());
}
}
输出:
5-小红
10-王五
20-李四
30-张三
-
Comparator接口有一个**
Compare(Object obj1,Object obj2)**方法用来排序;- 用于比较两个对象;
- -1表示当前对象小于,0表示等于,1表示大于。
ArrayList<Integer> arrayList = new ArrayList<Integer>(); arrayList.add(-1); arrayList.add(3); arrayList.add(3); arrayList.add(-5); arrayList.add(7); arrayList.add(4); arrayList.add(-9); arrayList.add(-7); // 定制排序的用法 Collections.sort(arrayList, new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o2.compareTo(o1); } }); System.out.println("定制排序后:"); System.out.println(arrayList);
List
特点:
- List集合类中元素是有序的(按插入顺序排序),且可以重复的(null也可以);
- 每个元素多有对应的索引
| 子类 | 描述 | 效率 |
|---|---|---|
| ArrayList | 基于动态数组的有序集合。 | 高 |
| LinkedList | 基于双向链表的有序集合。 | 高 |
| Vector | 与 ArrayList 类似,但是线程安全。 | 低 |
常见方法:
| 方法 | 说明 |
|---|---|
| add(E element) | 向列表末尾添加一个元素。 |
| add(int index, E element) | 在指定位置插入一个元素。 |
| get(int index) | 获取指定索引位置的元素。 |
| set(int index, E element) | 替换指定索引位置的元素。 |
| remove(int index) | 移除指定索引位置的元素。 |
| size() | 获取列表的大小。 |
| contains(Object obj) | 检查列表是否包含指定的元素。 |
| indexOf(Object obj) | 获取指定元素在列表中的第一个出现位置的索引。 |
| clear() | 清空列表中的所有元素。 |
| toArray() | 将列表转换为数组。 |
| addAll(Collection<? extends E> c) | 将另一个集合的所有元素添加到当前列表中。 |
ArrayList
数据结构:
ArrayList的数据结构由数组实现数据存储,如下图所示:
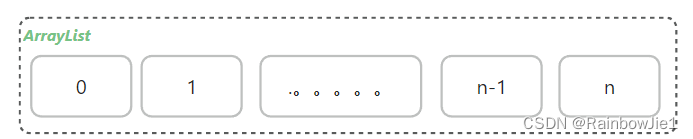
特点:
- 线程不安全(执行效率高),在多线程的情况下不建议使用。
源码分析:
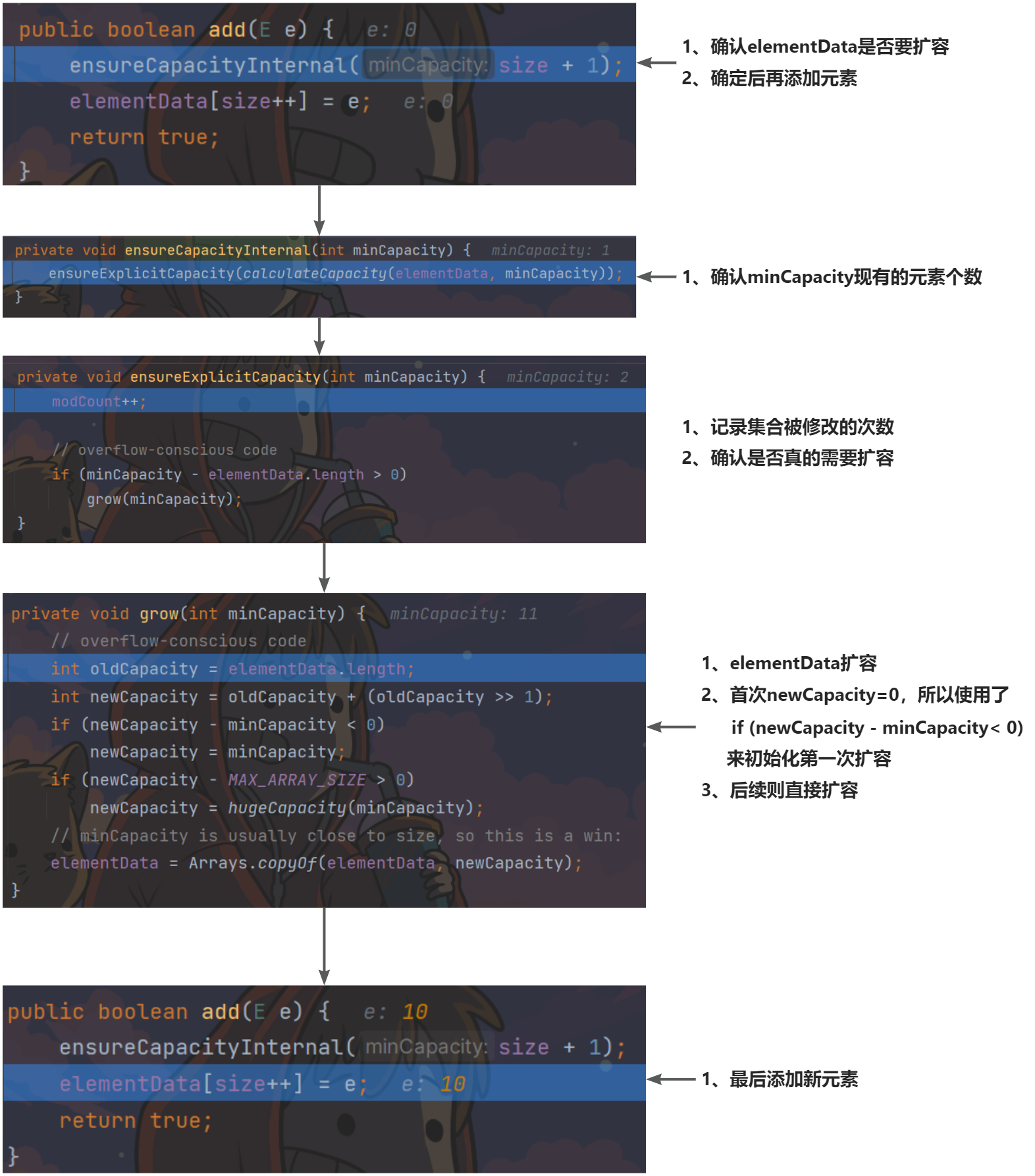
-
ArrayList中维护了一个
Object类型的数组elementData[],存储元素。transient Object[] elementData; // transient,表示该变量不会被序列化 -
创建ArrayList对象
默认使用的无参构造,则初始化容量为elementData=0,第一次添加元素,则扩容elementData=10,如果还需要扩容,则扩容elementData为1.5倍。List list=new ArrayList();源码如下:

-
添加元素
list.add(元素);源码如下:
LinkedList
数据结构:
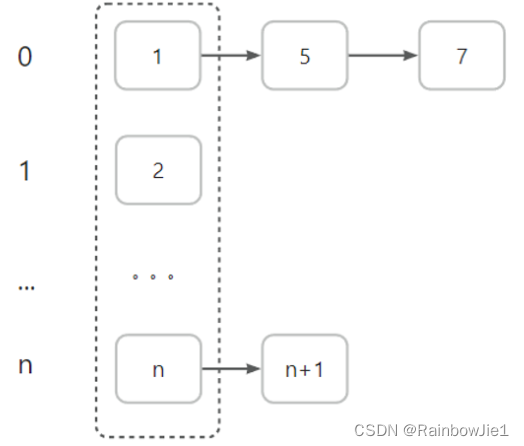
- LinkedList底层实现了双向链表、双端队列特点。
特点:
- 可以添加任意元素(可以重复),包括null;
- 线程不安全,没有实现线程同步
Vector
数据结构:
- Vector底层是一个对象数组,
protected Object[] elementData;
特点:
- Vector是线程同步的,即线程安全,操作方法带有synchronized(支持线程同步和互斥);
public synchronized void addElement(E obj) { modCount++; ensureCapacityHelper(elementCount + 1); elementData[elementCount++] = obj; }
Set
特点:
- 无序(添加的顺序和访问的顺序不一致)、没有索引
- 不允许重读元素,最多包含一个null;
HashSet
数据结构:
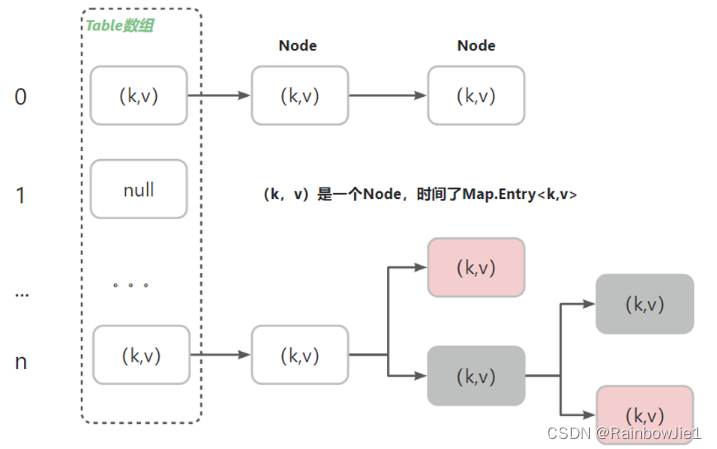
HashSet的底层实际上是HashMap,HashMap的底层是(数组+链表+红黑树)

-
元素存储到Key;
HashSet 中每个元素都被存储为键-值对,但值部分被设置为一个固定的常量PRESENT(通常是**
Object**类型的占位符),而不是实际的值。HashSet<String> set = new HashSet<>(); set.add("test");底层键值对=<test,PRESENT>
扩容机制:
HashSet默认数组长度=11,每次扩充为原来的2n+1。
-
添加元素
- 当HashSet添加元素时,首先会计算元素的哈希码hashCode,并根据哈希码确定元素在哈希表中的位置;
//计算hashCode static final int hash(Object key) { int h; // key.hashCode():返回散列值也就是hashcode // ^:按位异或 // >>>:无符号右移,忽略符号位,空位都以0补齐 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } -
判断链表是否有相同元素:对于多个对象来说hashCode可能相同,所以使用
equals()方法来判断对象是否相同- 不相同:直接添加;
- 相同:不添加。
-
如果有链表长度>8,且table的长度>64,先进行扩容,然后将链表转为红黑树。
Map
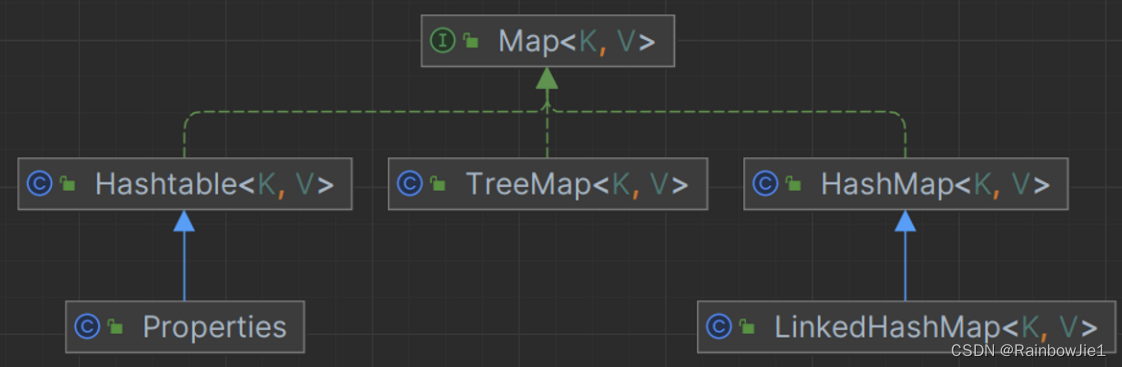
特点:
- 数据存储结构是键值对:<key,value>;
- key不允许重复;
- value可以重复;
- key可以为null,但只能有一个null,value可以有多个null;
常用方法:
| 方法 | 说明 |
|---|---|
| put | 添加键值对。 |
| remove | 根据键删除键值对。 |
| get | 根据键获取值。 |
| size | 获取键值对的个数。 |
| isEmpty | 判断键值对个数是否为0。 |
| clear | 清除所有键值对。 |
| containsKey | 查找指定键是否存在。 |
遍历
KeySet
keySet() 方法是 Java 中 Map 接口的一种方式,通过该方法可以获取包含映射中所有键的集合,然后你可以使用这个键集合来遍历 Map 中的键值对。以下是示例代码:
import java.util.*;
public class MapTraversalExample {
public static void main(String[] args) {
// 创建一个示例的Map
Map<String, Integer> map = new HashMap<>();
map.put("Alice", 25);
map.put("Bob", 30);
map.put("Charlie", 35);
// 使用keySet()方法获取键集合
Set<String> keySet = map.keySet();
// 遍历键集合并访问Map中的键值对
for (String key : keySet) {
Integer value = map.get(key);
System.out.println("Key: " + key + ", Value: " + value);
}
}
}
EntrySet
entrySet() 是 Java 中 Map接口提供的一个方法,它返回一个包含 Map中所有键值对(Entry 对象)的集合(Set)。通过这个方法,你可以方便地遍历 Map 中的所有键值对,而不仅仅是键或值。
以下是使用 entrySet()方法遍历 Map的示例代码:
import java.util.*;
public class MapTraversalExample {
public static void main(String[] args) {
// 创建一个示例的Map
Map<String, Integer> map = new HashMap<>();
map.put("Alice", 25);
map.put("Bob", 30);
map.put("Charlie", 35);
// 使用entrySet()方法获取键值对的集合
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
// 遍历键值对集合并访问Map中的键值对
for (Map.Entry<String, Integer> entry : entrySet) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("Key: " + key + ", Value: " + value);
}
}
}
迭代器
要使用迭代器遍历Map,你可以通过entrySet()方法获取包含键值对(Map.Entry对象)的集合,然后使用迭代器遍历这个集合。以下是一个示例:
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class MapIteratorExample {
public static void main(String[] args) {
// 创建一个示例的Map
Map<String, Integer> map = new HashMap<>();
map.put("Alice", 25);
map.put("Bob", 30);
map.put("Charlie", 35);
// 获取包含键值对的集合
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
// 获取迭代器对象
Iterator<Map.Entry<String, Integer>> iterator = entrySet.iterator();
// 使用迭代器遍历Map
while (iterator.hasNext()) {
Map.Entry<String, Integer> entry = iterator.next();
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("Key: " + key + ", Value: " + value);
}
}
}
HashMap
在Map接口的基础上,HashMap还有如下特点:
- HashMap没有实现同步,因此线程是不安全的,方法没有做互斥同步。
数据结构:
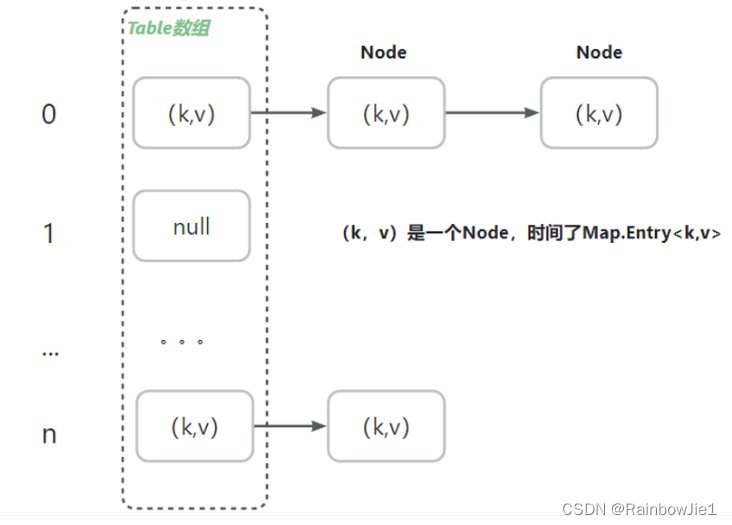
- (k,v)是一个Node,实现了Map.Entry<k,v>(遍历Map)。
- 在jdk8(数组+链表+红黑树)之后,当一个链表的长度>8,并且table的长度>64,会先进行数组扩容,然后将链表转为红黑树。
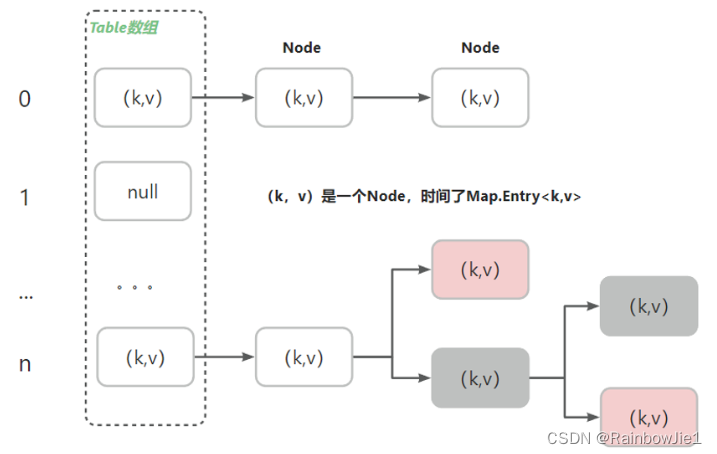
扩容机制:
- HashMap默认初始化数组长度=16,当超过时,会将容量变为原来的2倍
HashTable
特点:
在Map接口的基础上,HashTable还有如下特点:
- HashTable的线程是安全的,内部方法基本使用
synchronized修饰; - 由于存在线程同步机制,在数据操作上效率较低。
- HashTable基本已经被淘汰!!
TreeMap
特点:
在Map接口的基础上,HashTable还有如下特点:
- TreeMap 中的键(key)是有序的,它们按照键的自然顺序(或者根据自定义的比较器)排列。
- TreeMap使用默认的自然排序(如果key实现了Comparable接口);
- 可以传入一个自定义的比较器(Comparator)来定义键的排序方式。
小结
Java集合框架为开发人员提供了强大的工具,以满足各种数据处理需求。了解不同集合类型的特性和适用场景对于编写高效和可维护的Java应用程序至关重要。通过选择合适的数据结构和算法,开发人员可以更轻松地解决各种问题。