flink 部署模式和运行时架构(会话模式、单作业模式、应用模式,JobManager、TaskManager,YARN 模式部署以及运行时架构)
1. 部署模式(抽象的概念)
1.1 会话模式(Session Mode)
会话模式,需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业。集群启动时所有资源就已经确定,所以所有提交的作业会竞争集群中的资源。
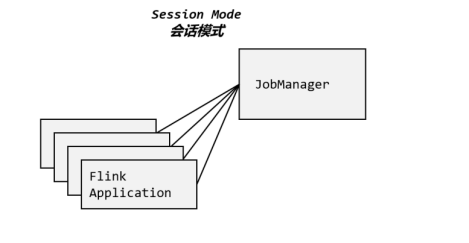
集群的生命周期是超越于作业之上的,作业结束了就释放资源,集群依然正常运行。当然:因为资源是共享的,所以资源不够了,提交新的作业就会失败。另外,同一个 TaskManager 上可能运行了很多作业,如果其中一个发生故障导致 TaskManager 宕机,那么所有作业都会受到影响
会话模式适合于单个规模小、执行时间短的大量作业
1.2 单作业模式(Per-Job Mode)
单作业模式是严格的一对一,集群只为这个作业而生。由客户端运行应用程序,然后启动集群,作业被提交给 JobManager,进而分发给 TaskManager 执行。作业作业完成后,集群就会关闭,所有资源会被释放。每个作业都有它自己的 JobManager管理,占用独享的资源,即使发生故障,它的TaskManager 宕机也不会影响其他作业。
单作业模式在生产环境运行更加稳定,是实际应用的首选模式
注:
Flink 本身无法直接运行单作业模式,需要借助一些资源管理框架来启动集群,如 YARN
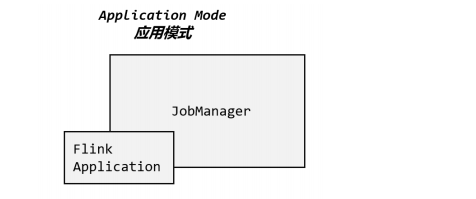
1.3 应用模式(Application Mode)
应用代码在客户端上执行,然后由客户端提交给 JobManager,客户端需要占用大量网络带宽用于下载依赖和把二进制数据发送给JobManager;并且提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
解决办法就是,直接把应用提交到 JobManger 上运行。为每一个提交的应用单独启动一个JobManager,也就是创建一个集群。这个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了
1.4 总结
在会话模式下,集群的生命周期独立于集群上运行的任何作业的生命周期,并且提交的所有作业共享资源。而单作业模式为每个提交的作业创建一个集群,带来了更好的资源隔离,这时集群的生命周期与作业的生命周期绑定。最后,应用模式为每个应用程序创建一个会话集群,在 JobManager 上直接调用应用程序的 main()方法
2. 系统架构
2.1 整体构成
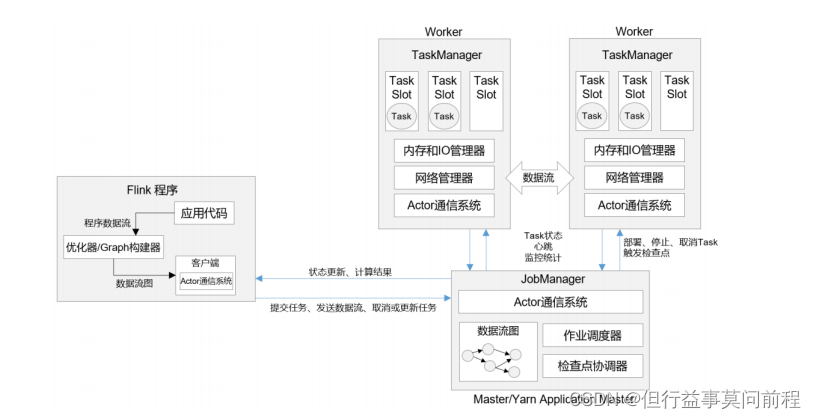
Flink 的运行时架构中,最重要的就是两大组件:作业管理器(JobManger)和任务管理器(TaskManager)。对于一个提交执行的作业,JobManager 是真正意义上的“管理者”(Master),负责管理调度,所以在不考虑高可用的情况下只能有一个;而 TaskManager 是“工作者”(Worker、Slave),负责执行任务处理数据,所以可以有一个或多个。
注:
attached mode (default): The yarn-session.sh client submits the Flink cluster to YARN, but the client keeps running, tracking the state of the cluster. If the cluster fails, the client will show the error. If the client gets terminated, it will signal the cluster to shut down as well.
detached mode (-d or --detached): The yarn-session.sh client submits the Flink cluster to YARN, then the client returns. Another invocation of the client, or YARN tools is needed to stop the Flink cluster.
客户端并不是处理系统的一部分,它只负责作业的提交。具体来说,就是调用程序的 main 方法,将代码转换成“数据流图”(Dataflow Graph),并最终生成作业图(JobGraph),一并发送给 JobManager。提交之后,任务的执行其实就跟客户端没有关系了;可以选择断开与 JobManager 的连接, 也可以继续保持连接。在命令提交作业时,加上的-d 参数,就是表示分离模式(detached mode),也就是断开连接
2.1.1 作业管理器(JobManager)
JobManger 包含 3 个不同的组件:

1. JobMaster
JobMaster 是 JobManager 中最核心的组件,负责处理单独的作业(Job)。所以JobMaster和具体的 Job 是一一对应的,多个 Job 可以同时运行在一个 Flink 集群中, 每个 Job 都有一个自己的 JobMaster。在作业提交时,JobMaster 会先接收到要执行的应用,包括:Jar 包,数据流图(dataflow graph),和作业图(JobGraph)。JobMaster 会把 JobGraph 转换成一个物理层面的数据流图,这个图被叫作“执行图”(ExecutionGraph),它包含了所有可以并发执行的任务。 JobMaster 会向资源管理器(ResourceManager)发出请求,申请执行任务必要的资源。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的 TaskManager 上。而在运行过程中,JobMaster 会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调
2. 资源管理器(ResourceManager)
ResourceManager 主要负责资源的分配和管理,在 Flink 集群中只有一个。所谓“资源”,主要是指 TaskManager 的任务槽(task slots)。任务槽就是 Flink 集群中的资源调配单元,包含了机器用来执行计算的一组 CPU 和内存资源。每一个任务(Task)都需要分配到一个 slot 上执行。注意要把 Flink 内置的 ResourceManager 和其他资源管理平台(比如 YARN)的ResourceManager 区分开。Flink 的 ResourceManager,针对不同的环境和资源管理平台有不同的具体实现。在 Standalone 部署时,因为 TaskManager 是单独启动的(没有Per-Job 模式),所以 ResourceManager 只能分发可用TaskManager 的任务槽,不能单独启动新TaskManager。而在有资源管理平台时,就不受此限制。当新的作业申请资源时,ResourceManager 会将有空闲槽位的 TaskManager 分配给 JobMaster。如果ResourceManager 没有足够的任务槽,它还可以向资源提供平台发起会话,请求提供启动TaskManager 进程的容器。另外,ResourceManager 还负责停掉空闲的 TaskManager,释放计算资源
3. 分发器(Dispatcher)
Dispatcher 主要负责提供一个 REST 接口,用来提交应用,并且负责为每一个新提交的作业启动一个新的 JobMaster 组件。Dispatcher 也会启动一个 Web UI,用来方便地展示和监控作业执行的信息。Dispatcher 在架构中并不是必需的,在不同的部署模式下可能会被忽略掉。
2.1.2 任务管理器(TaskManager)
TaskManager 是 Flink 中的工作进程,数据流的具体计算就是它来做的,所以也被称为“Worker”。Flink 集群中必须至少有一个 TaskManager;当然由于分布式计算的考虑,通常会有多个 TaskManager 运行,每一个 TaskManager 都包含了一定数量的任务槽(task slots)。Slot是资源调度的最小单位,slot 的数量限制了 TaskManager 能够并行处理的任务数量。启动之后,TaskManager 会向资源管理器注册它的 slots;收到资源管理器的指令后,TaskManager 就会将一个或者多个槽位提供给 JobMaster 调用,JobMaster 就可以分配任务来执行了。在执行过程中,TaskManager 可以缓冲数据,还可以跟其他运行同一应用的 TaskManager交换数据
2.2 高层级抽象视角
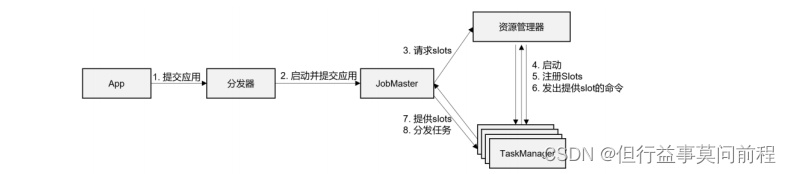
(1) 一般情况下,由客户端(App)通过分发器提供的 REST 接口,将作业提交给JobManager
(2)由分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster
(3)JobMaster 将 JobGraph 解析为可执行的 ExecutionGraph,得到所需的资源数量,然后向资源管理器请求资源(slots)。
(4)资源管理器判断当前是否由足够的可用资源;如果没有,启动新的 TaskManager
(5)TaskManager 启动之后,向 ResourceManager 注册自己的可用任务槽(slots)
(6)资源管理器通知 TaskManager 为新的作业提供 slots
(7)TaskManager 连接到对应的 JobMaster,提供 slots
(8)JobMaster 将需要执行的任务分发给 TaskManager
(9)TaskManager 执行任务,互相之间可以交换数据
3. 独立模式(Standalone)
3.1 概念
独立模式(Standalone)是部署 Flink 最基本最简单的方式:所需要的所有 Flink 组件,都只是操作系统上运行的一个 JVM 进程。
独立模式不依赖任何外部的资源管理平台;如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式一般只用在开发测试或作业非常少的场景下。
3.2 会话模式部署、单作业模式部署(不支持)、应用模式部署
4. YARN 模式部署和运行架构
4.1 概念
YARN 上部署的过程是:客户端把 Flink 应用提交给 Yarn 的 ResourceManager, Yarn 的 ResourceManager 会向 Yarn 的 NodeManager 申请容器。在这些容器上,Flink 会部署JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在 JobManger 上的作业所需要的 Slot 数量动态分配 TaskManager 资源
yarn模式部署
检查hadoop环境
echo $HADOOP_CLASSPATH
4.2 会话模式
4.2.1 部署
启动集群:
(1)启动 hadoop 集群(HDFS, YARN)。
(2)执行脚本命令向 YARN 集群申请资源,开启一个 YARN 会话,启动 Flink 集群
bin/yarn-session.sh -d -nm cz -qu hello
可用参数解读:
-d:分离模式,Flink YARN 客户端后台运行
-jm(–jobManagerMemory):配置 JobManager 所需内存,默认单位 MB
-nm(–name):配置在 YARN UI 界面上显示的任务名
-qu(–queue):指定 YARN 队列名
-tm(–taskManager):配置每个 TaskManager 所使用内存
注:
Flink1.11.0 版本不再使用-n 参数和-s 参数分别指定 TaskManager 数量和 slot 数量,YARN 会按照需求动态分配 TaskManager 和 slot
YARN Session 启动之后会给出一个 web UI 地址以及一个 YARN application ID

上述启动的yarn模式flink集群:
web UI为http://hadoop104:42947
停止集群echo "stop" | ./bin/yarn-session.sh -id application_1654053140138_0001
强制停止yarn application -kill application_1654053140138_0001
提交作业:
(1)通过 Web UI 提交作业
(2)通过命令行提交作业
bin/flink run [OPTIONS] <jar-file> <arguments>
4.2.2 运行时架构
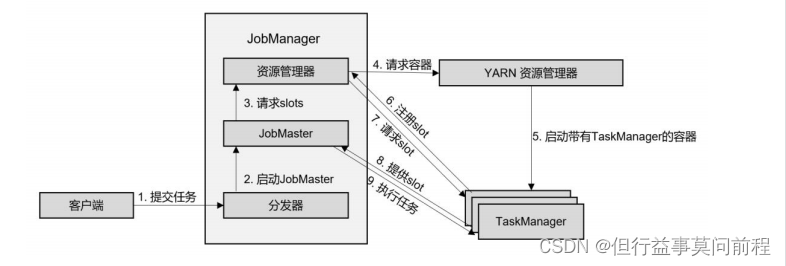
(1)客户端通过 REST 接口,将作业提交给分发器
(2)分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster
(3)JobMaster 向资源管理器请求资源(slots)
(4)资源管理器向 YARN 的资源管理器请求 container 资源
(5)YARN 启动新的 TaskManager 容器
(6)TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽
(7)资源管理器通知 TaskManager 为新的作业提供 slots
(8)TaskManager 连接到对应的 JobMaster,提供 slots
(9)JobMaster 将需要执行的任务分发给 TaskManager,执行任务
4.3 单作业模式
4.3.1 部署
在 YARN 环境中,由于有了外部平台做资源调度,所以可以直接向 YARN 提交一个单独的作业,从而启动一个 Flink 集群
(1)执行命令提交作业
bin/flink run -d -t yarn-per-job -creview.part2.StreamWordCount libexec/FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar
(2)在 YARN 的 ResourceManager 界面查看执行情况

点击 Tracking URL

(3)使用命令行查看或取消作业
bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY

bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
4.3.2 运行时架构
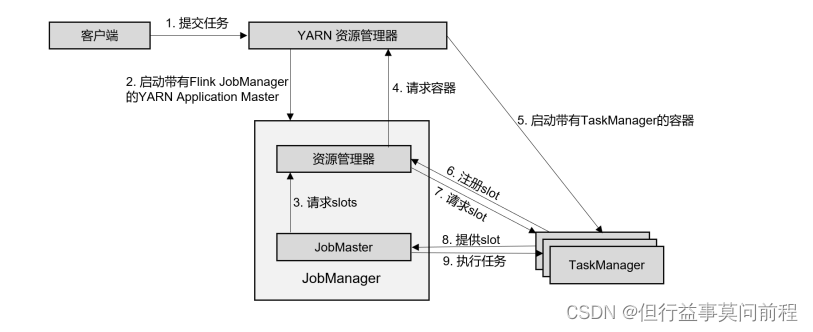
(1)客户端将作业提交给 YARN 的资源管理器,这一步中会同时将 Flink 的 Jar 包和配置上传到 HDFS,以便后续启动 Flink 相关组件的容器
(2)YARN 的资源管理器分配 Container 资源,启动 Flink JobManager,并将作业提交给JobMaster。这里省略了 Dispatcher 组件
(3)JobMaster 向资源管理器请求资源(slots)
(4)资源管理器向 YARN 的资源管理器请求 container 资源
(5)YARN 启动新的 TaskManager 容器
(6)TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽
(7)资源管理器通知 TaskManager 为新的作业提供 slots
(8)TaskManager 连接到对应的 JobMaster,提供 slots
(9)JobMaster 将需要执行的任务分发给 TaskManager,执行任务
4.4 应用模式
4.4.1 部署
(1)执行命令提交作业
bin/flink run-application -t yarn-application -c review.part2.StreamWordCount libexec/FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar

(2)在命令行中查看或取消作业
bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY

$ bin/flink cancel -t yarn-application
-Dyarn.application.id=application_XXXX_YY <jobId>
(3)可通过 yarn.provided.lib.dirs 配置选项指定位置,将 jar 上传到远程
4.4.2 运行时架构
应用模式与单作业模式的提交流程非常相似,只是初始提交给 YARN 资源管理器的不再是具体的作业,而是整个应用。一个应用中可能包含了多个作业,这些作业都将在 Flink 集群中启动各自对应的 JobMaster
4.5 高可用
Standalone 模式中, 同时启动多个 JobManager, 一个为leader,其他为standby, 当 leader 挂了, 其他的才会有一个成为 leader。 而 YARN 的高可用是只启动一个 Jobmanager, 当这个 Jobmanager 挂了之后, YARN 会再次启动一个, 所以其实是利用的 YARN 的重试次数来实现的高可用
(1)在 yarn-site.xml 中配置
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>
(2)在 flink-conf.yaml 中配置。
yarn.application-attempts: 3
high-availability: zookeeper
high-availability.storageDir: hdfs目录
high-availability.zookeeper.quorum: hadoop102:2181,hadoop103:2181,hadoop104:2181
high-availability.zookeeper.path.root: /flink-yarn
(3)启动 yarn-session
(4)杀死 JobManager, 查看复活情况
注意:
yarn-site.xml 中配置的是 JobManager 重启次数的上限, flink-conf.xml 中的次数应该小于这个值
ps:参考书籍pdf:
链接:百度网盘
提取码:1256