数据科学中的数据库简介
推荐:使用 NSDT场景编辑器 快速搭建3D应用场景

用于高效视频、AI 和图形的通用加速器
数据科学中的数据库简介
数据科学涉及从大量数据中提取价值和见解,以推动业务决策。它还涉及使用历史数据构建预测模型。数据库有助于对如此大量的数据进行有效的存储、管理、检索和分析。
因此,作为一名数据科学家,您应该了解数据库的基础知识。因为它们支持存储和管理大型复杂数据集,从而实现高效的数据探索、建模和获取见解。让我们在本文中更详细地探讨这一点。
我们将首先讨论数据科学的基本数据库技能,包括用于数据检索、数据库设计、优化等的 SQL。然后,我们将介绍主要数据库类型、它们的优点和用例。
数据科学的基本数据库技能
数据库技能对于数据科学家至关重要,因为它们为有效的数据管理、分析和解释提供了基础。
以下是数据科学家应该了解的关键数据库技能的细分:

图片来源:作者
尽管我们试图将数据库概念和技能分类到不同的存储桶中,但它们是一致的。在处理项目时,您通常需要在此过程中了解或学习它们。
现在让我们回顾一下以上每个内容。
1. 数据库类型和概念
作为数据科学家,您应该对不同类型的数据库(例如关系数据库和NoSQL数据库)及其各自的用例有很好的了解。
2.SQL(结构化查询语言)用于数据检索
通过实践实现的SQL熟练程度是数据空间中任何角色的必备条件。您应该能够编写和优化 SQL 查询,以从数据库中检索、筛选、聚合和联接数据。
了解查询执行计划以及能够识别和解决性能瓶颈也很有帮助。
3. 数据建模与数据库设计
除了查询数据库表之外,还应了解数据建模和数据库设计的基础知识,包括实体关系 (ER) 图、架构设计和数据验证约束。
您还应该能够设计支持高效查询和数据存储以进行分析的数据库架构。
4. 数据清理和转换
作为数据科学家,您必须对原始数据进行预处理并将其转换为适合分析的格式。数据库可以支持数据清理、转换和集成任务。
因此,您应该知道如何从各种来源提取数据,将其转换为合适的格式,并将其加载到数据库中进行分析。熟悉 ETL 工具、脚本语言(Python、R)和数据转换技术非常重要。
5. 数据库优化
您应该了解优化数据库性能的技术,例如创建索引、非规范化和使用缓存机制。
为了优化数据库性能,使用索引来加快数据检索速度。正确的索引通过允许数据库引擎快速找到所需的数据来缩短查询响应时间。
6. 数据完整性和质量检查
通过定义数据输入规则的约束来维护数据完整性。唯一约束、非空约束和检查约束等约束可确保数据的准确性和可靠性。
事务用于确保数据一致性,保证将多个操作视为单个原子单元。
7. 与工具和语言的集成
数据库可以与流行的分析和可视化工具集成,使数据科学家能够有效地分析和展示他们的发现。因此,您应该知道如何使用Python等编程语言连接到数据库并与之交互,并执行数据分析。
熟悉Python的pandas,R和可视化库等工具也是必要的。
总结:了解各种数据库类型、SQL、数据建模、ETL 过程、性能优化、数据完整性以及与编程语言的集成是数据科学家技能组合的关键组成部分。
在本介绍性指南的其余部分,我们将重点介绍基本的数据库概念和类型。
图片来源:作者
关系数据库基础
关系数据库是一种数据库管理系统 (DBMS),它使用包含行和列的表以结构化的方式组织和存储数据。流行的RDBMS包括PostgreSQL,MySQL,Microsoft SQL Server和Oracle。
让我们通过示例深入了解一些关键的关系数据库概念。
关系数据库表
在关系数据库中,每个表代表一个特定的实体,表之间的关系是使用键建立的。
若要了解如何在关系数据库表中组织数据,从实体和属性开始会很有帮助。
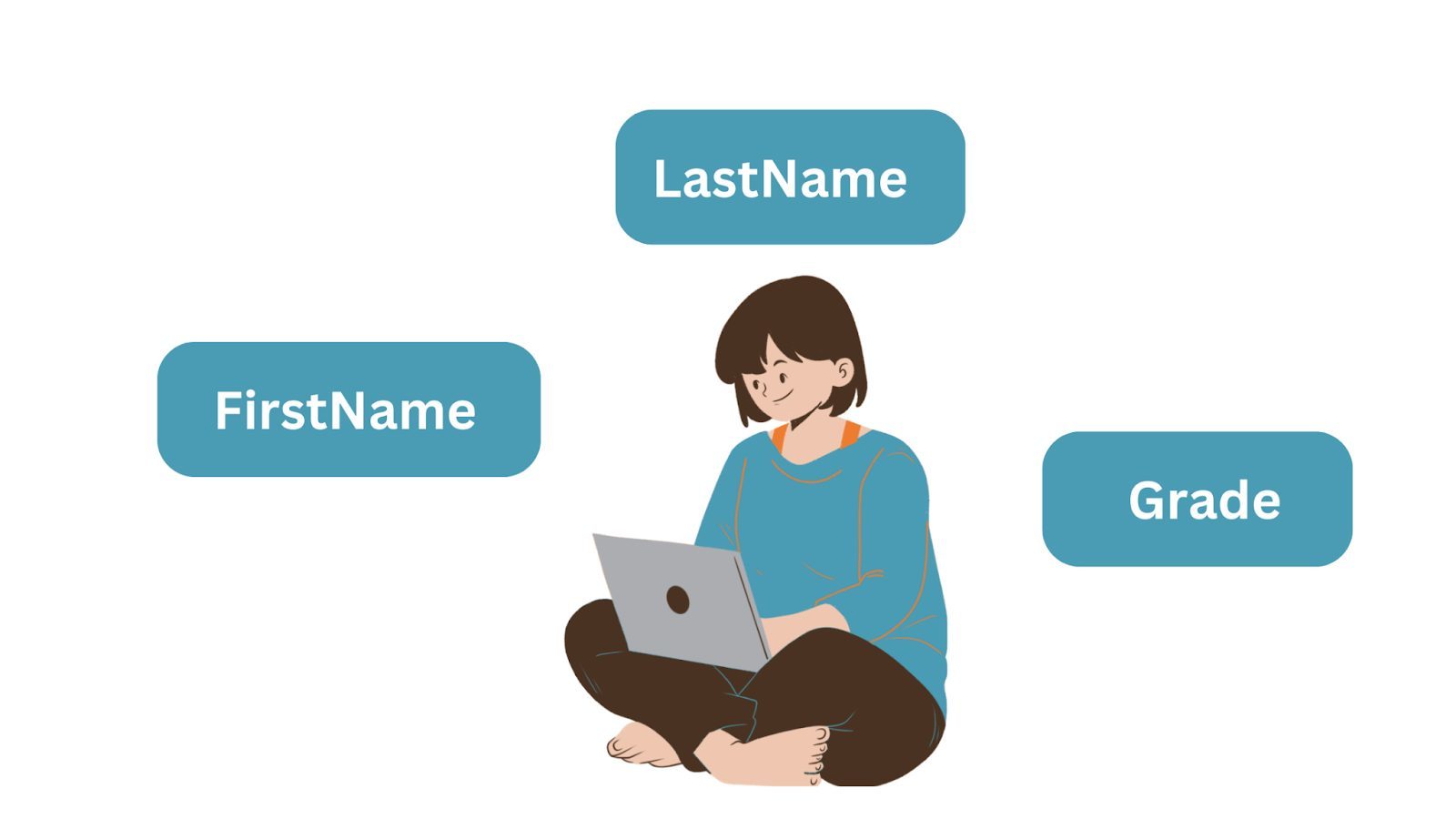
您通常需要存储有关对象的数据:学生、客户、订单、产品等。这些对象是实体,它们具有属性。
让我们以一个简单的实体为例,它是一个具有三个属性的“学生”对象:名字、姓氏和成绩。存储数据时 实体成为数据库表,属性成为列名或字段。每一行都是实体的一个实例。
图片来源:作者
关系数据库中的表由行和列组成:
- 这些行也称为记录或元组,并且
- 这些列称为属性或字段。
下面是一个简单的“学生”表的示例:
| 学生证 | 名 | 姓氏 | 年级 |
| 1 | 珍 | 史密斯 | A+ |
| 2 | 艾米丽 | 棕色 | 一个 |
| 3 | 杰克 | 威廉姆斯 | B+ |
在此示例中,每行表示一个学生,每列表示有关该学生的一条信息。
了解键
键用于唯一标识表中的行。两种重要的密钥类型包括:
- 主键:主键唯一标识表中的每一行。它确保数据完整性并提供引用特定记录的方法。在“学生”表中,“学生 ID”可以是主键。
- 外键:外键在表之间建立关系。它引用另一个表的主键,用于链接相关数据。例如,如果我们有另一个名为“课程”的表,则“课程”表中的“学生 ID”列可能是引用“学生”表中“学生 ID”的外键。
关系
关系数据库允许您在表之间建立关系。以下是最重要和最常发生的关系:
- 一对一关系:在一对一关系下,表中的每个记录都与数据库中另一个表中的一条(且仅一条)记录相关。例如,包含每个学生的其他信息的“学生详细信息”表可能与“学生”表具有一对一的关系。
- 一对多关系:第一个表中的一条记录与第二个表中的多条记录相关。例如,“课程”表可以与“学生”表具有一对多关系,其中每个课程都与多个学生相关联。
- 多对多关系:两个表中的多个记录相互关联。为了表示这一点,使用了中间表,通常称为联结表或链接表。例如,“学生课程”表可以在学生和课程之间建立多对多关系。
正常化
规范化(通常在数据库优化技术下讨论)是以最小化数据冗余和提高数据完整性的方式组织数据的过程。它涉及将大型表分解为较小的相关表。每个表应表示单个实体或概念,以避免重复数据。
例如,如果我们考虑“学生”表和假设的“地址”表,规范化可能涉及使用自己的主键创建一个单独的“地址”表,并使用外键将其链接到“学生”表。
关系数据库的优点和局限性
以下是关系数据库的一些优点:
- 关系数据库提供了一种结构化和有组织的方式来存储数据,从而可以轻松定义不同类型数据之间的关系。
- 它们支持事务的 ACID 属性(原子性、一致性、隔离性、持久性),确保数据保持一致。
另一方面,它们具有以下限制:
- 关系数据库在水平可扩展性方面存在挑战,这使得处理大量数据和高流量负载变得具有挑战性。
- 它们还需要严格的架构,这使得在不修改架构的情况下适应数据结构的变化变得具有挑战性。
- 关系数据库专为具有明确定义关系的结构化数据而设计。它们可能不太适合存储非结构化或半结构化数据,如文档、图像和多媒体内容。
探索 NoSQL 数据库
NoSQL 数据库不会以熟悉的行列格式将数据存储在表中(因此是非关系数据库)。术语“NoSQL”代表“不仅仅是SQL”,表明这些数据库与传统的关系数据库模型不同。
NoSQL数据库的主要优点是它们的可扩展性和灵活性。与传统的关系数据库相比,这些数据库旨在处理大量非结构化或半结构化数据,并提供更灵活和可扩展的解决方案。
NoSQL 数据库包含各种数据库类型,这些数据库类型在数据模型、存储机制和查询语言方面有所不同。NoSQL数据库的一些常见类别包括:
- 键值存储
- 文档数据库
- 列系列数据库
- 图形数据库。
现在,让我们回顾一下每个NoSQL数据库类别,探索它们的特征,用例以及示例,优点和局限性。
键值存储
键值存储将数据存储为简单的键和值对。它们针对高速读写操作进行了优化。它们适用于缓存、会话管理和实时分析等应用程序。
但是,除了基于密钥的检索之外,这些数据库的查询功能有限。所以他们不适合复杂的关系。
Amazon DynamoDB 和 Redis 是常用的键值存储。
文档数据库
文档数据库以 JSON 和 BSON 等文档格式存储数据。每个文档可以有不同的结构,允许嵌套和复杂的数据。其灵活的模式允许轻松处理半结构化数据,支持不断发展的数据模型和层次结构关系。
它们特别适用于内容管理、电子商务平台、目录、用户配置文件和数据结构不断变化的应用程序。对于涉及多个文档的复杂联接或复杂查询,文档数据库可能效率不高。
MongoDB和Couchbase是流行的文档数据库。
列系列存储(宽列存储)
列族存储,也称为列式数据库或面向列的数据库,是一种 NoSQL 数据库,它以面向列的方式组织和存储数据,而不是关系数据库的传统面向行的方式。
列系列存储适用于涉及对大型数据集运行复杂查询的分析工作负荷。在列系列数据库中,通常更有效地执行聚合、筛选和数据转换。它们有助于管理大量半结构化或稀疏数据。
Apache Cassandra,ScyllaDB和HBase是一些列系列存储。
图形数据库
图形数据库分别对节点和边中的数据和关系进行建模。来表示复杂的关系。这些数据库支持高效处理复杂关系和强大的图形查询语言。
您可以猜到,这些数据库适用于社交网络、推荐引擎、知识图谱,以及通常具有复杂关系的数据。
流行的图形数据库的例子是Neo4j和Amazon Neptune。
有许多NoSQL数据库类型。那么我们如何决定使用哪一个呢?井。答案是:视情况而定。
每个类别的NoSQL数据库都提供独特的功能和优势,使其适用于特定的用例。通过考虑访问模式、可伸缩性要求和性能注意事项来选择合适的 NoSQL 数据库非常重要。
总而言之:NoSQL数据库在灵活性,可扩展性和性能方面具有优势,使其适用于广泛的应用程序,包括大数据,实时分析和动态Web应用程序。但是,它们在数据一致性方面需要权衡取舍。
NoSQL数据库的优点和局限性
以下是NoSQL数据库的一些优点:
- NoSQL数据库专为水平可扩展性而设计,允许它们处理大量数据和流量。
- 这些数据库允许灵活和动态的架构。它们具有灵活的数据模型以适应各种数据类型和结构,使其非常适合非结构化或半结构化数据。
- 许多NoSQL数据库设计为在分布式和容错环境中运行,即使在硬件故障或网络中断的情况下也能提供高可用性。
- 它们可以处理非结构化或半结构化数据,使其适用于处理不同数据类型的应用程序。
一些限制包括:
- NoSQL数据库优先考虑可扩展性和性能,而不是严格的ACID合规性。这可能会导致最终一致性,并且可能不适合需要强数据一致性的应用程序。
- 由于NoSQL数据库具有不同的API和数据模型,因此缺乏标准化可能会使在数据库之间切换或无缝集成它们变得具有挑战性。
需要注意的是,NoSQL数据库不是一个放之四海而皆准的解决方案。NoSQL 和关系数据库之间的选择取决于应用程序的特定需求,包括数据量、查询模式和可伸缩性要求等。
关系数据库与 NoSQL 数据库
让我们总结一下到目前为止讨论的差异:
| 特征 | 关系数据库 | NoSQL 数据库 |
| 数据模型 | 表格结构(表) | 多样化的数据模型(文档、键值对、图形、列等) |
| 数据一致性 | 一致性强 | 最终一致性 |
| 图式 | 定义完善的架构 | 灵活或无架构 |
| 数据关系 | 支持复杂的关系 | 因类型而异(有限或显式关系) |
| 查询语言 | 基于 SQL 的查询 | 特定查询语言或 API |
| 灵活性 | 对于非结构化数据而言不那么灵活 | 适用于多种数据类型,包括 |
| 使用案例 | 结构良好的数据,复杂的事务 | 大规模、高吞吐量、实时应用程序 |
关于时间序列数据库的说明
作为数据科学家,您还将处理时序数据。时序数据库也是非关系数据库,但具有更具体的用例。
它们需要支持存储、管理和查询带时间戳的数据点(随时间记录的数据点),例如传感器读数和股票价格。它们提供用于存储、查询和分析基于时间的数据模式的专用功能。
时间序列数据库的一些示例包括InfluxDB,QuestDB和TimescaleDB。
结论
在本指南中,我们介绍了关系数据库和NoSQL数据库。还值得注意的是,除了流行的关系和NoSQL类型之外,您还可以探索更多数据库。NewSQL数据库(如CockroachDB)提供了SQL数据库的传统优势,同时提供了NoSQL数据库的可扩展性和性能。
您还可以使用内存中数据库,该数据库主要在计算机的主内存 (RAM) 中存储和管理数据,而不是在磁盘上存储数据的传统数据库。这种方法提供了显著的性能优势,因为与磁盘存储相比,可以在内存中执行更快的读取和写入操作。