ETF场内基金:AI量化投资最佳切入点(数据篇)
原创文章第77篇,专注“个人成长与财富自由、世界运作的逻辑, AI量化投资”。
关于量化的基础知识,前面说得差不多了。
后面要开始实战。
量化的细分市场很多,如下图所示:
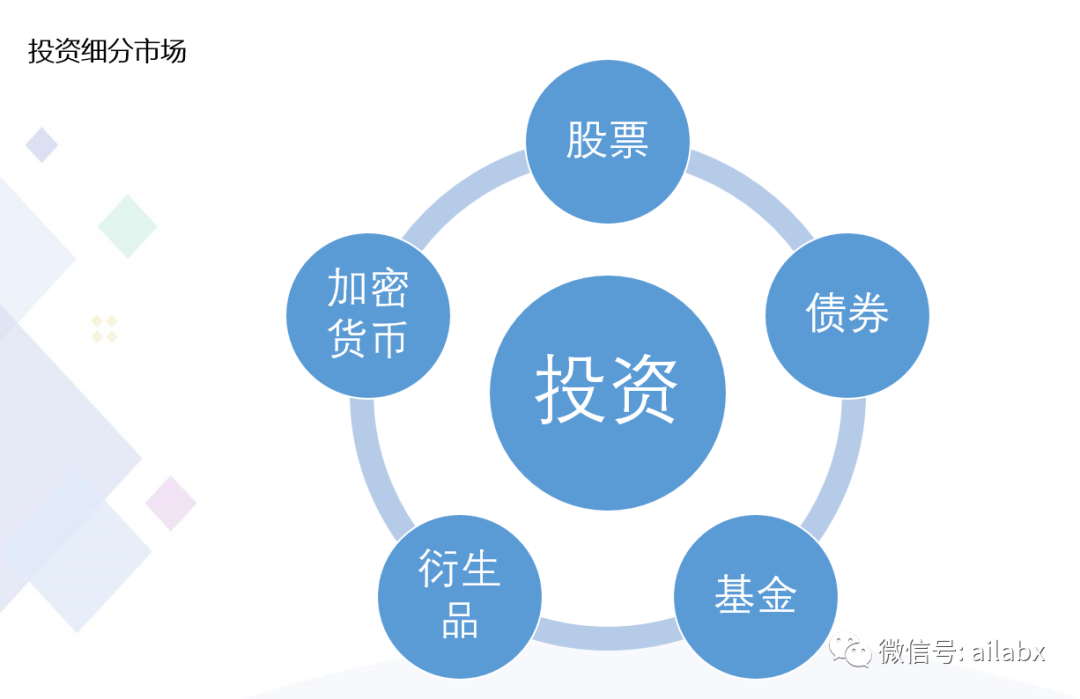
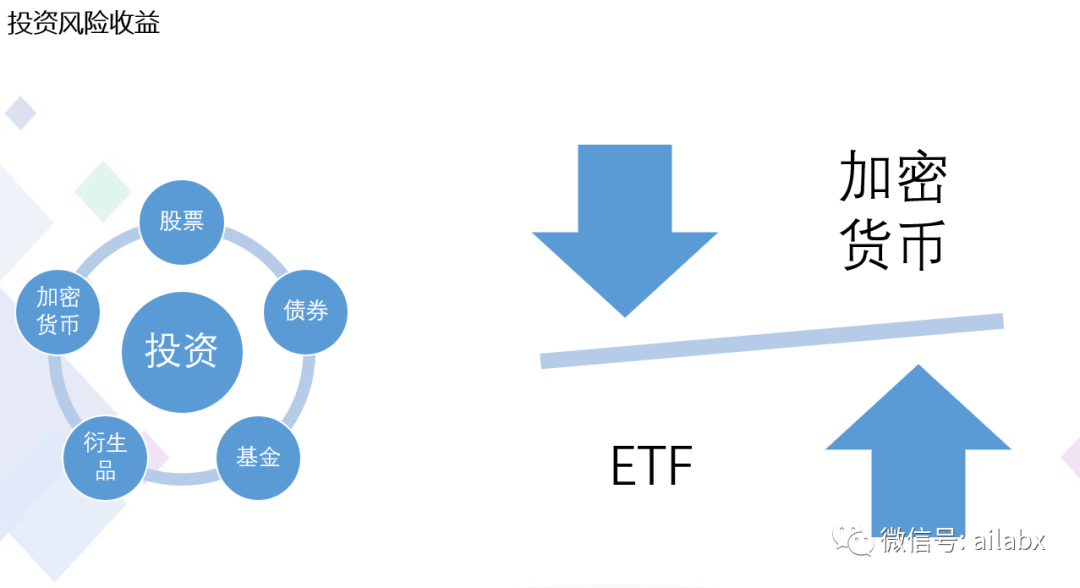
再从风险收益来看,从基金到加密货币,从“保守”到“激进”。
这里指的保守,当然是“主动管理”里的保守。还是更保守的就是“大类资产配置”。
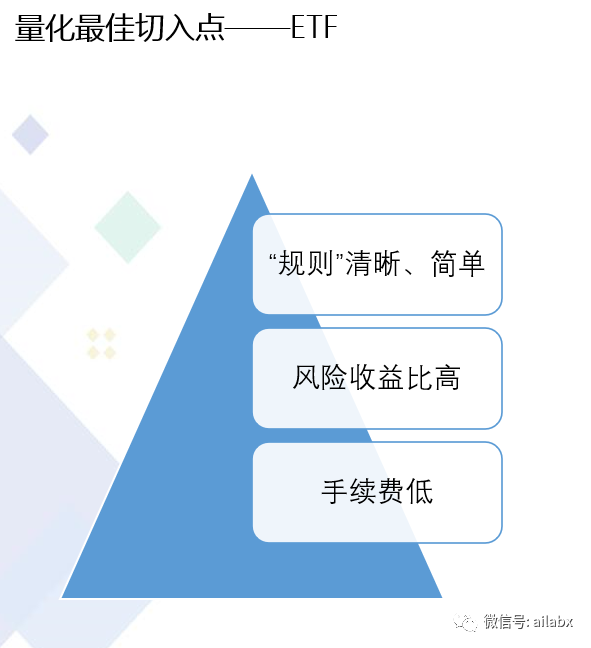
关于实战,我选择的“战场”是ETF。
一般的专栏讲量化,要么期货(CTA),更多是股票。为何我跳过股票而选择ETF?
我们说过,越宏观的东西规律越稳定,越微观越随机。ETF背后是指数,可以是行业,可能是市值,也可能是红利这样的smart beta。在一定的时间段相对稳定 。相对下来,股票背后是一家家公司,就算白酒都挺好,但不是谁都能成为茅台,更何况商战信息千变万化,要判断一家公司未来前景谈何容易。
指数基金是跨品种(货币,债券,可转债,FOF,商品,REIT…),跨市场的,覆盖香港,美国、日本,越南,德国…) ,具备跨市场和品类配置,对冲的可能。
ETF与主动基金相比规则更透明,不太依赖基金公司和基金经理。回头看,确实能找到不少多年超过市场基准的明星基金经理,但往前看,你很难看清。去年风格切换,很多明星基金经理就没有反应过来。我们很难判断是正常回调,还是他从此泯然于众人。而ETF就是被动执行规则,因子规律清晰。另外,指数基金长生不死,做长线配置非常合适。
场内交易与场外基金相比手续费更低,部分还可以T+0交易。大类资产配置走场外可以定投,要主动管理走场内,可以灵活交易。
01 数据准备
场内基金列表:
df = get_etf_basics()
df['_id'] = df['ts_code']
from common.mongo_utils import write_df
write_df('basic_etfs', df, drop_tb_if_exist=True)
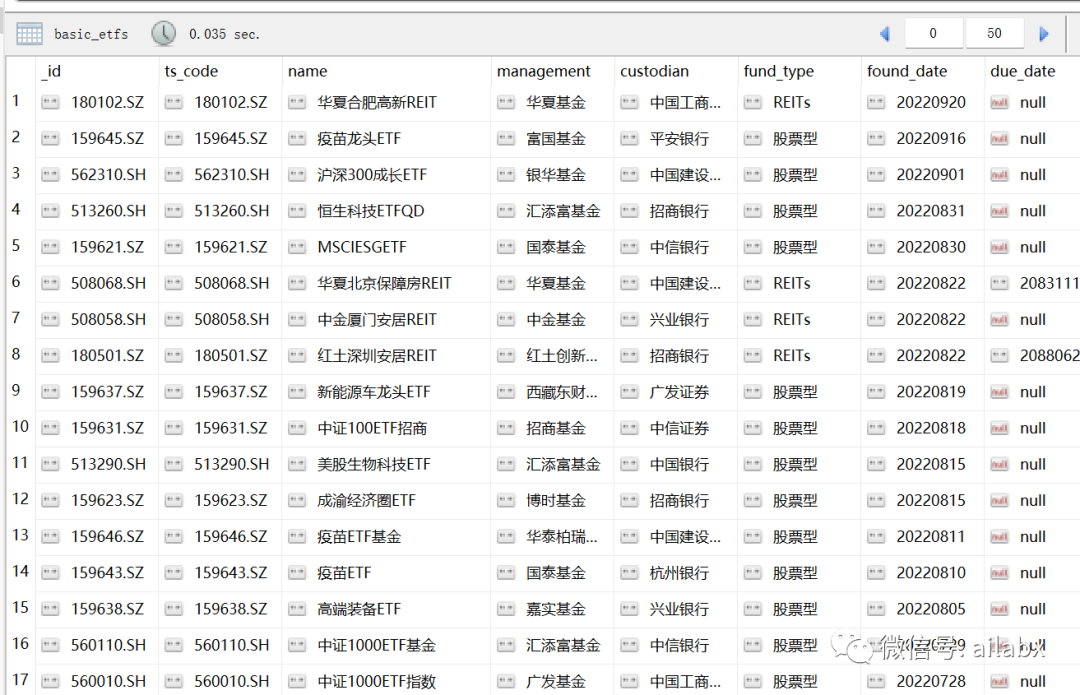
一共1184支可交易的场内基金。
基金净值处理有两个细节。
ts的接口每次只能取最新的800行,一些历史较久的基金,需要多次读取数据。

另外,复权因子每次限制2000行,同时复权因子需要还原补充到时间序列里。
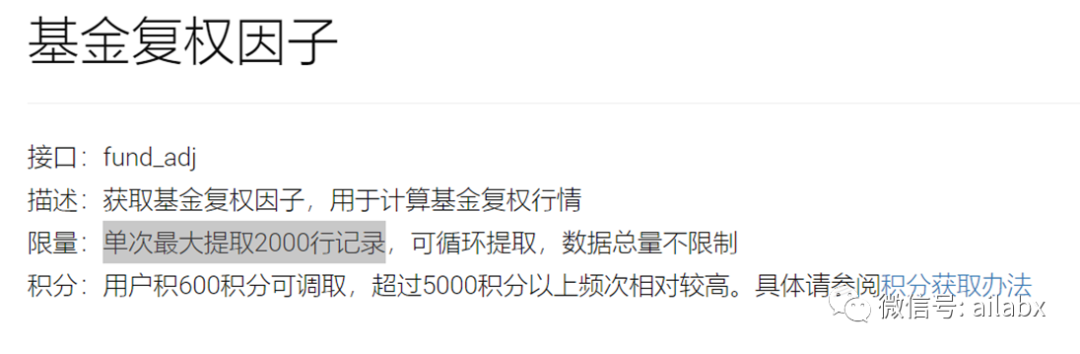
这里用好两个参数,offset和limit。
offset从0开始,每次limit读800,offset递增800,若没有数据返回就退出循环。
def get_etf_quotes(code, date_start="", offset=0, limit=800):
# 拉取数据
df = pro.fund_daily(**{
"trade_date": "",
"start_date": "{}".format(date_start),
"end_date": "",
"ts_code": "{}".format(code),
"limit": limit,
"offset": offset
}, fields=[
"ts_code",
"trade_date",
"open",
"high",
"low",
"close",
"vol",
"amount"
])
df.dropna(inplace=True)
if len(df) == 0:
return None
return df
def get_all_quotes(code):
offset = 0
df = get_etf_quotes(code, offset=0)
print(df)
all = [df]
while (df is not None):
print('===========================offset====================', offset)
offset += 800
df = get_etf_quotes(code, offset=offset)
all.append(df)
df_all = pd.concat(all)
df_all.dropna(inplace=True)
df_all.set_index('trade_date', inplace=True)
return df_all
以“后复权”的方式保留——我们回测时,都以“后复权”的价格进行。
02 Arctic:基于mongo的列存数据库
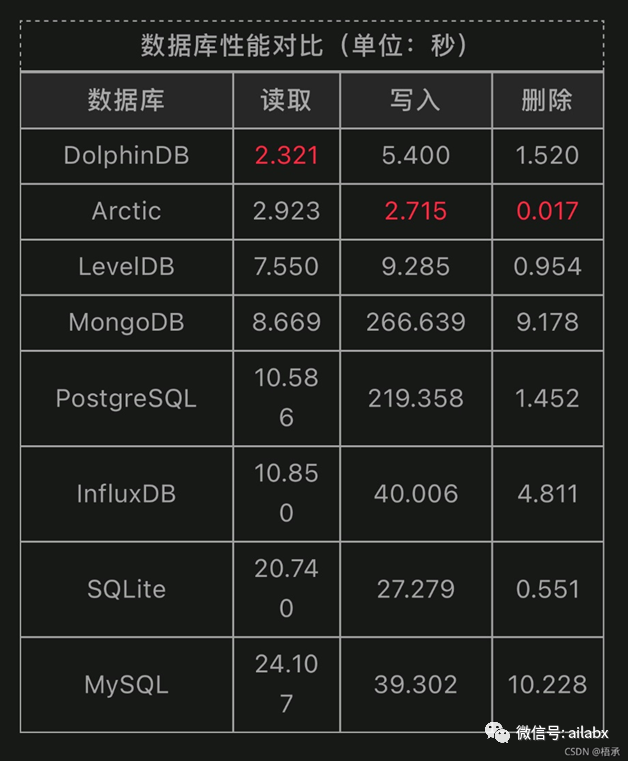
Arctic由MAN AHL于2012年开发,并于2015年开源,Arctic 构建在MongoDB之上,针对数值数据的高性能数据库。
在量化投资中,可以用来存储海量的Tick级行情数据。它支持 Pandas、 numpy 数组和 pickle 对象,并支持其他数据类型和版本控制。每个客户机每秒可以查询数百万行,网络带宽达到10倍的压缩,磁盘达到10倍的压缩,每个 MongoDB 实例每秒可扩展到数亿行。
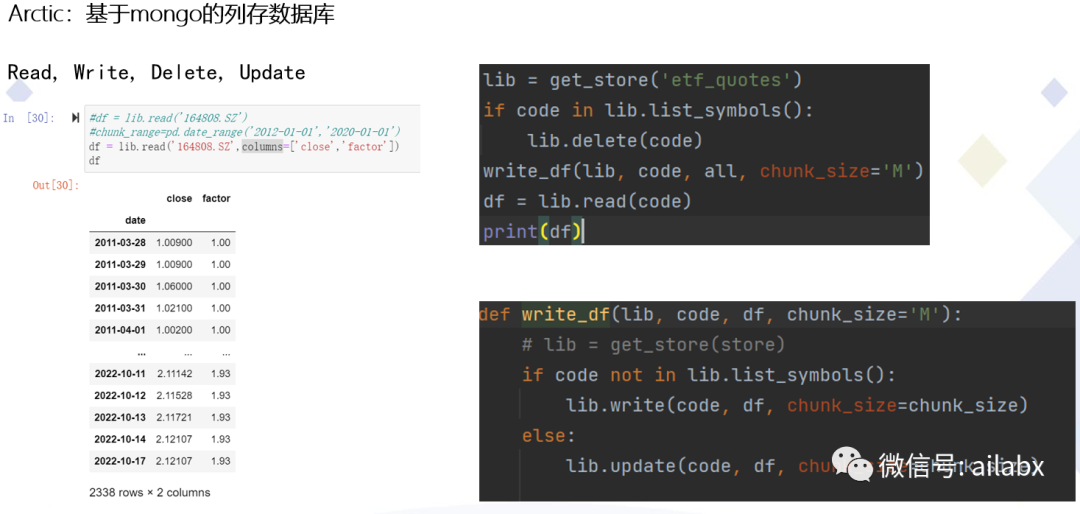
列存数据库写入,读出都非常快,一会会功夫,1000多支场内基金的历史数据就都入库了。
明天基于arctic,结合backtrader构建策略,开始实战。