Python 之 Pandas DataFrame 数据类型的简介、创建的列操作
文章目录
- DataFrame 是 Pandas 的重要数据结构之一,也是在使用 Pandas 进行数据分析过程中最常用的结构之一,可以这么说,掌握了 DataFrame 的用法,你就拥有了学习数据分析的基本能力。
一、DataFrame 结构简介
- DataFrame 是一个表格型的数据结构,既有行标签(index),又有列标签(columns),它也被称异构数据表。
- 所谓异构,指的是表格中每列的数据类型可以不同,比如可以是字符串、整型或者浮点型等。其结构图示意图,如下所示:
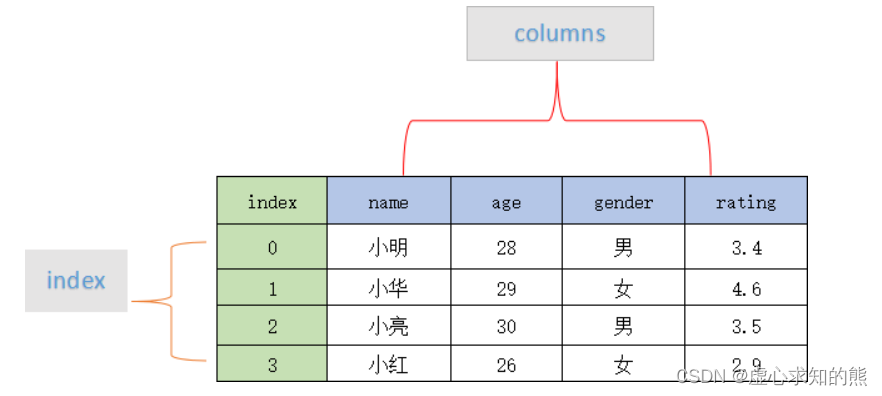
- 表格中展示了某个销售团队个人信息和绩效评级(rating)的相关数据。数据以行和列形式来表示,其中每一列表示一个属性,而每一行表示一个条目的信息。
- 下表展示了上述表格中每一列标签所描述数据的数据类型,如下所示:
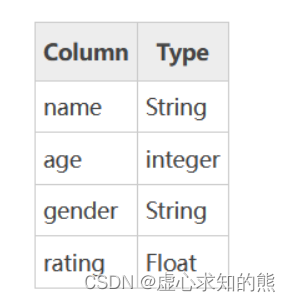
- DataFrame 的每一列数据都可以看成一个 Series 结构,只不过,DataFrame 为每列数据值增加了一个列标签。
- 因此 DataFrame 其实是从 Series 的基础上演变而来,并且他们有相同的标签,在数据分析任务中 DataFrame 的应用非常广泛,因为它描述数据的更为清晰、直观。
- 通过示例对 DataFrame 结构做进一步讲解。 下面展示了一张学生评分表,如下所示:
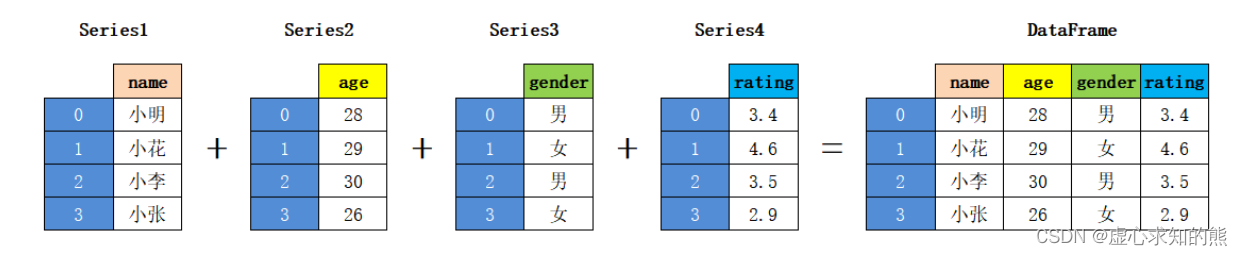
- 同 Series 一样,DataFrame 自带行标签索引,默认为隐式索引即从 0 开始依次递增,行标签与 DataFrame 中的数据项一一对应。上述表格的行标签从 0 到 3,共记录了 4 条数据(图中将行标签省略)。当然你也可以用“显式索引”的方式来设置行标签。
- 下面对 DataFrame 数据结构的特点做简单地总结,如下所示:
- (1) DataFrame 每一列的标签值允许使用不同的数据类型。
- (2) DataFrame 是表格型的数据结构,具有行和列。
- (3) DataFrame 中的每个数据值都可以被修改。
- (4) DataFrame 结构的行数、列数允许增加或者删除。
- (5) DataFrame 有两个方向的标签轴,分别是行标签和列标签。
- (6) DataFrame 可以对行和列执行算术运算。
二、DataFrame 对象创建
- Pandas DataFrame 是一个二维的数组结构,类似二维数组。
- DataFrame 的语法模板如下:
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)
其参数含义如下:
- data 表示输入的数据,可以是 ndarray,series,list,dict,标量以及一个 DataFrame。
- index 表示行标签,如果没有传递 index 值,则默认行标签是 RangeIndex(0, 1, 2, …, n),n 代表 data 的元素个数。
- columns 表示列标签,如果没有传递 columns 值,则默认列标签是 RangeIndex(0, 1, 2, …, n)。
- dtype 表示要强制的数据类型。只允许使用一种数据类型。如果没有定义强制的数据类型,就会自行推断。
- copy 表示从输入复制数据。对于 dict 数据,copy=True,表示重新复制一份。对于 DataFrame 或 ndarray 输入,类似于 copy=False,在原数据中进行操作。
- 在开始之前,我们需要先引入 numpy 和 pandas 库。
import numpy as np
import pandas as pd
1. 使用普通列表创建
- 使用 DataFrame 数据结构进行输出。
- 在这里我们并没有设置 index 和 columns,因此,他们就默认从 0 开始。
- DataFrame 不会输出数据类型。
data = [1,2,3,4,5]
df = pd.DataFrame(data)
print(df)
# 0
#0 1
#1 2
#2 3
#3 4
#4 5
- 使用 Series 数据结构进行输出。
- Series 会输出对应的数据类型。
data = [1,2,3,4,5]
df = pd.Series(data)
print(df)
#0 1
#1 2
#2 3
#3 4
#4 5
#dtype: int64
2. 使用嵌套列表创建
- 列表中每个元素代表一行数据,如果我们不分配列标签,他们会默认从 0 开始进行计数。
data = [['xiaowang',20],['Lily',30],['Anne',40]]
df = pd.DataFrame(data)
print(df)
# 0 1
#0 xiaowang 20
#1 Lily 30
#2 Anne 40
- 当我们分配列标签时,会按我们分配的进行输出。
- 这里需要注意的是,我们分配的列标签必须和列数对应。
data = [['xiaowang',20],['Lily',30],['Anne',40]]
df = pd.DataFrame(data,columns=['Name','Age'])
print(df)
# Name Age
#0 xiaowang 20
#1 Lily 30
#2 Anne 40
3 指定数值元素的数据类型为 float
- 需要注意的是,dtype 只能设置一个,设置多个列的数据类型,需要使用其他方式。
- 当我们分配列标签时,满足我们设定的数据类型会自动使用,不满足则会自动识别。
data = [['xiaowang', 20, "男", 5000],['Lily', 30, "男", 8000],['Anne', 40, "女", 10000]]
df = pd.DataFrame(data,columns=['Name','Age',"gender", "salary"], dtype=int)
print(df)
print(df['salary'].dtype)
# Name Age gender salary
#0 xiaowang 20 男 5000
#1 Lily 30 男 8000
#2 Anne 40 女 10000
#float64
4. 字典嵌套列表创建
- data 字典中,键对应的值的元素长度必须相同(也就是列表长度相同)。
- 如果传递了索引,那么索引的长度应该等于数组的长度;如果没有传递索引,那么默认情况下,索引将是 RangeIndex(0.1…n),其中 n 代表数组长度。
- 这里我们需要注意的时,字典在 python 3.7 以后是有顺序的。
- 例如,我们通过字典创建 DataFrame,输出行标签和列标签。
data = {'Name':['关羽', '刘备', '张飞', '曹操'],'Age':[28,34,29,42]}
df = pd.DataFrame(data)
print(df)
print(df.index)
print(df.columns)
# Name Age
#0 关羽 28
#1 刘备 34
#2 张飞 29
#3 曹操 42
#RangeIndex(start=0, stop=4, step=1)
#Index(['Name', 'Age'], dtype='object')
- 注意:这里使用了默认行标签,也就是 RangeIndex(0.1…n)。它生成了 0,1,2,3,并分别对应了列表中的每个元素值。
5. 添加自定义的行标签
- 通过字典嵌套列表创建 DataFrame ,并定义我们的行标签,最后输出行标签和列标签。
data = {'Name':['关羽', '刘备', '张飞', '曹操'],'Age':[28,34,29,42]}
index = ["rank1", "rank2", "rank3", "rank4"]
df = pd.DataFrame(data, index=index)
print(df)
print(df.index)
print(df.columns)
# Name Age
#rank1 关羽 28
#rank2 刘备 34
#rank3 张飞 29
#rank4 曹操 42
#Index(['rank1', 'rank2', 'rank3', 'rank4'], dtype='object')
#Index(['Name', 'Age'], dtype='object')
6. 列表嵌套字典创建 DataFrame 对象
- 列表嵌套字典可以作为输入数据传递给 DataFrame 构造函数。默认情况下,字典的键被用作列名。
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data, index=['first', 'second'])
print(df)
# a b c
#first 1 2 NaN
#second 5 10 20.0
- 注意,如果其中某个元素值缺失,也就是字典的 key 无法找到对应的 value,将使用 NaN 代替。
- 如何使用列表嵌套字典创建一个 DataFrame 对象,可以设置结果需要那些列。
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df1 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b'])
df2 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b1'])
print("===========df1============")
print(df1)
print("===========df2============")
print(df2)
#===========df1============
# a b
#first 1 2
#second 5 10
#===========df2============
# a b1
#first 1 NaN
#second 5 NaN
7. Series 创建 DataFrame 对象
- 也可以传递一个字典形式的 Series,从而创建一个 DataFrame 对象,其输出结果的行索引是所有 index 的合集。
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print(df)
type(np.NaN)
# one two
#a 1.0 1
#b 2.0 2
#c 3.0 3
#d NaN 4
#float
- 注意:对于 one 列而言,此处虽然显示了行索引 ‘d’,但由于没有与其对应的值,所以它的值为 NaN。
- 当我们需要解决不同列的数据类型时,可以使用设置自定义数据类型。
data = {
"Name":pd.Series(['xiaowang', 'Lily', 'Anne']),
"Age":pd.Series([20, 30, 40], dtype=float),
"gender":pd.Series(["男", "男", "女"]),
"salary":pd.Series([5000, 8000, 10000], dtype=float)
}
df = pd.DataFrame(data)
df
# Name Age gender salary
#0 xiaowang 20.0 男 5000.0
#1 Lily 30.0 男 8000.0
#2 Anne 40.0 女 10000.0
三、DataFrame 列操作
- DataFrame 可以使用列标签来完成数据的选取、添加和删除操作。下面依次对这些操作进行介绍。
1. 选取数据列
- 可以使用列索引,轻松实现数据选取。
- 我们通过字典创建 DataFrame,定义行标签,单独选取每一列并输出。
data = {'Name':['关羽', '刘备', '张飞', '曹操'],'Age':[28,34,29,42]}
index = ["rank1", "rank2", "rank3", "rank4"]
df = pd.DataFrame(data, index=index)
print(df)
print("=========df['Name']:取得Name列===============")
print(df['Name'])
print("=========df['Age']:取得Age列===============")
print(df['Age'])
# Name Age
#rank1 关羽 28
#rank2 刘备 34
#rank3 张飞 29
#rank4 曹操 42
#=========df['Name']:取得Name列===============
#rank1 关羽
#rank2 刘备
#rank3 张飞
#rank4 曹操
#Name: Name, dtype: object
#=========df['Age']:取得Age列===============
#rank1 28
#rank2 34
#rank3 29
#rank4 42
#Name: Age, dtype: int64
- 我们也可以同时选取很多列。
print("=========df[['Name', 'Age']]:df选取多列===============")
print(df[['Name', 'Age']])
#=========df[['Name', 'Age']]:df选取多列===============
# Name Age
#rank1 关羽 28
#rank2 刘备 34
#rank3 张飞 29
#rank4 曹操 42
- 这里需要注意的是,列不是能使用切片选取多列。
print("=========df不能使用切片选取多列===============")
print(df['Name': 'Age'])
#=========df不能使用切片选取多列===============
#Empty DataFrame
#Columns: [Name, Age]
#Index: []
- 如果我直接通过标签位置去获取列,会报错。
df[1]
2. 列添加
- 使用 columns 列索引标签可以实现添加新的数据列,示例如下。
- 首先,我们创建初始数据。
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print(df)
# one two
#a 1.0 1
#b 2.0 2
#c 3.0 3
#d NaN 4
- 然后使用 df[‘列’]= 值,插入新的数据列。
print ("====通过Series添加一个新的列====:")
df['three']=pd.Series([10,20,30],index=['a','b','c'])
print(df)
#====通过Series添加一个新的列====:
# one two three
#a 1.0 1 10.0
#b 2.0 2 20.0
#c 3.0 3 30.0
#d NaN 4 NaN
- 我们也可以将已经存在的数据列相加运算,从而创建一个新的列。
print ("======将已经存在的数据列相加运算,从而创建一个新的列:=======")
df['four']=df['one']+df['three']
print(df)
#======将已经存在的数据列相加运算,从而创建一个新的列:=======
# one two three four
#a 1.0 1 10.0 11.0
#b 2.0 2 20.0 22.0
#c 3.0 3 30.0 33.0
#d NaN 4 NaN NaN
- 如果我们新添加的列当中出现新的行标签,就不会显示出来。
df['error']=pd.Series([10,20,30],index=['b','a','s3'])
print(df)
# one two three four error
#a 1.0 1 10.0 11.0 20.0
#b 2.0 2 20.0 22.0 10.0
#c 3.0 3 30.0 33.0 NaN
#d NaN 4 NaN NaN NaN
3. insert() 方法添加
- 在上述示例中,我们初次使用了 DataFrame 的算术运算,这和 NumPy 非常相似。
- 除了使用 df[]=value 的方式外,您还可以使用 insert() 方法插入新的列,其语法模板如下:
df.insert(loc, column, value, allow_duplicates=False)
- 其参数含义如下:
- loc 表示整型,插入索引,必须验证 0<=loc<=len(列)。
- column 表示插入列的标签,类型可以是字符串、数字或者散列对象。
- value 表示数值,必须是 Series 或者数组。
- allow_duplicates 表示是否允许重复,可以有相同的列标签数据,默认为 False。
- 具体可见如下例子,我们先生成初始数据,便于后续的操作。
info=[['王杰',18],['李杰',19],['刘杰',17]]
df=pd.DataFrame(info,columns=['name','age'])
print(df)
# name age
#0 王杰 18
#1 李杰 19
#2 刘杰 17
- 这里需要注意的是,我们使用 column 参数。数值 1 代表插入到 columns 列表的索引位置。其中,loc 代表整型,插入索引,必须验证 0<=loc<=len(列)。
df.insert(1,column=‘score’,value=[91,90,75])
print("=====df.insert插入数据:=======")
print(df)
#=====df.insert插入数据:=======
# name score age
#0 王杰 91 18
#1 李杰 90 19
#2 刘杰 75 17
- 当然,我们也可以添加重复列标签数据。
df.insert(1,column='score',value=[80,70,90],allow_duplicates=True)
print(df)
# name score score age
#0 王杰 80 91 18
#1 李杰 70 90 19
#2 刘杰 90 75 17
- 此时,如果我们单独提取出列标签是 score 的列,那么,两列就都会输出。
df['score']
#score score
#0 80 91
#1 70 90
#2 90 75
- 如果我们将 allow_duplicates 参数设置为 False,然后再插入具有相同列标签的数据,就会报错。
df.insert(1,column='score',value=[80,70,90])
# 错误 cannot insert name, already exists
4. 删除数据列
- 我们通过 del 和 pop() 都能够删除 DataFrame 中的数据列,但区别是,del 没有返回值,而 pop 有返回值,具体示例如下:
- 首先,我们创建初始数据,便于后面的对比操作。
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
'three' : pd.Series([10,20,30], index=['a','b','c'])}
df = pd.DataFrame(d)
print ("Our dataframe is:")
print(df)
#Our dataframe is:
# one two three
#a 1.0 1 10.0
#b 2.0 2 20.0
#c 3.0 3 30.0
#d NaN 4 NaN
- 我们使用 del 方法进行删除操作。
del df['one']
print("=======del df['one']=========")
print(df)
#=======del df['one']=========
# two three
#a 1 10.0
#b 2 20.0
#c 3 30.0
#d 4 NaN
- 我们使用 pop 方法进行删除操作。
- 由于,pop 方法可以返回我们删除的数据,因此,在一定程度上也可以用来提取数据,但是,他也会修改我们的源数据。
res_pop = df.pop('two')
print("=======df.pop('two')=========")
print(df)
print("=======res_pop = df.pop('two')=========")
print(res_pop)
#=======df.pop('two')=========
# three
#a 10.0
#b 20.0
#c 30.0
#d NaN
#=======res_pop = df.pop('two')=========
#a 1
#b 2
#c 3
#d 4
#Name: two, dtype: int64